目标检测技术演化:从R-CNN到Faster R-CNN
|
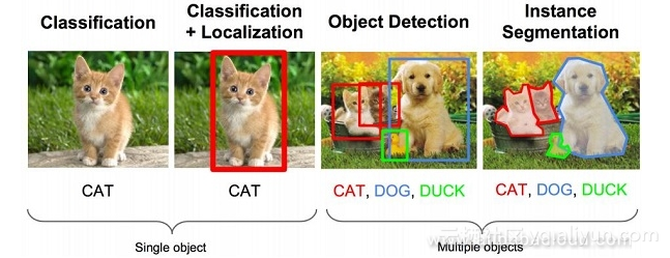
作者:【方向】 来源:云栖社区 原文链接: https://yq.aliyun.com/articles/619803?spm=a2c4e.11153940.bloghomeflow.332.162d291aRoS8gf 目标检测旨在准确地找到给定图片中物体的位置,并将其正确分类。准确地来讲,目标检测需要确定目标是什么以及对其定位。 然而,想要解决这个问题并不容易。因为,目标的大小,其在空间中的方向,其姿态,以及其在图片中的位置都是变化的。 这里有一张图片,我们需要识别图片中的物体,并且用方框将该物体圈出来。 图像识别(分类)
定位:
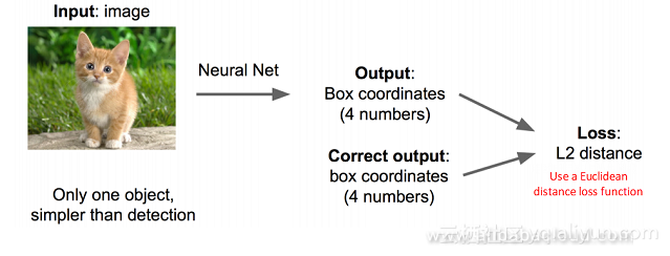
如今大火的卷积神经网络帮助我们很好地进行图像识别。但是,我们仍需要一些额外的功能来进行精确定位,深度学习在这里发挥了很好的作用。 在本文中,我们将从目标定位的角度入手探讨目标检测技术的发展。我们将按着如下的演化顺序讲述:R-CNN->SPP Net->Fast R-CNN-> Faster R-CNN 在开始前,我们将对基于区域的卷积神经网络(R-CNN)进行简单的介绍。 将定位看作回归问题如果我们将其看作是一个回归问题,则需要对(x,y,w,h)四个参数进行预测,从而得到方框所在位置。
步骤2
步骤3
步骤4
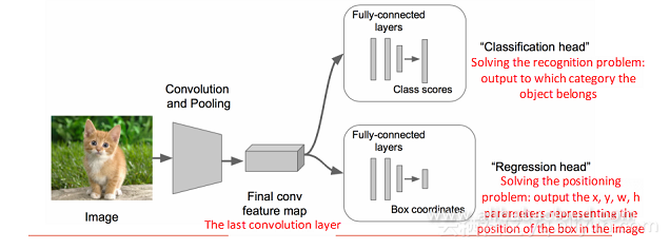
接着,我们将进行两次微调操作。第一次在AlexNet上进行,第二次将头部改为回归头。 回归部分加在哪里呢? 两种解决办法:
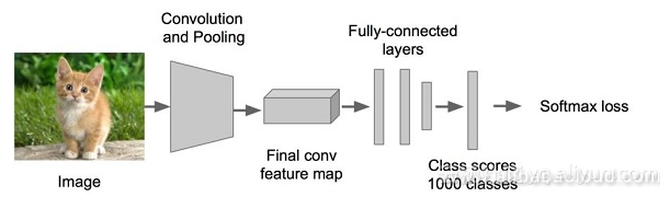
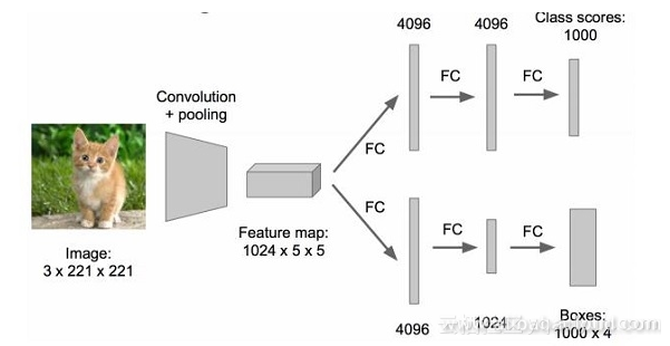
但是实现回归操作太困难了,我们需要找到一种方法将其变为分类问题。回归的训练参数收敛的时间要长得多,所以上面的网络采取了用分类的网络来计算网络共同部分的连接权值。 取图像窗口
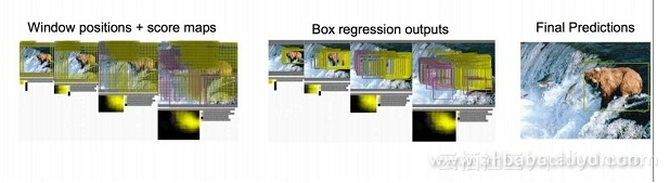
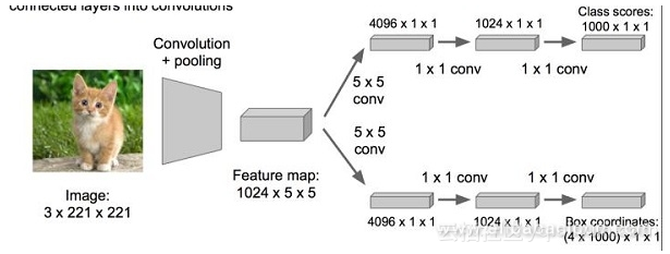
左上角的黑框:得分0.5 根据这些得分,我们选择右下角的黑框作为所要预测的目标位置。 注: 有的时候也会选择得分最高的两个方框,然后取两个方框的交集作为最终需要预测的位置。 问题: 方框的大小如何确定呢? 当取了不同的方框后,依次从左上角扫描到右下角。 总结: 对第一张图片,我们使用不同大小的方框(遍历整张图片)将图片截取出来,输入到CNN,然后CNN会输出这个框的分类以及这个框图片对应的(x,y,w,h)。 但是,这个方法太耗费时间了,需要做一些优化。最初的网络模型如下图所示: 所做优化:将全连接层改为为卷积层以提高速度。 当图中有多个物体存在的时候我们应该如何做呢?现在我们所要解决的问题就变成了:多个目标识别+定位。 现在我们还能将其看作分类问题么? 可是,将其看作分类问题的话会有如下矛盾产生:
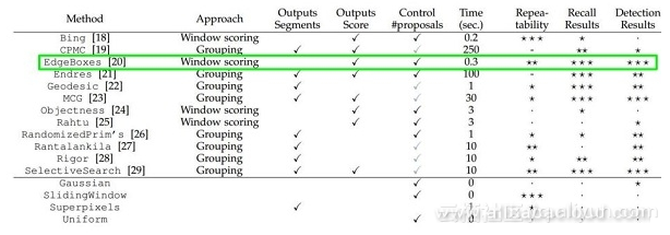
如果将其看作分类问题,我们能做哪些优化呢?我们并不想使用太多的方框在不同的位置间来回尝试。下面,给出了一种解决方案: 首先,我们需要找出包含所有目标的方框。其中有的方框会产生重叠或者互相包含,这样我们就不用枚举出所有的方框了。 对于候选框的获取,前人发现了很多种方法:比如EdgeBoxes和Selective Search。以下是候选方框获取方法的性能对比: 对于“选择性搜索”是如何选出所有候选方框这个问题,本文不作介绍,有兴趣的可以对其相关论文进行研究。 上述提及的思路推动了R-CNN的面世。让我们以同样的图片为例,对R-CNN进行讲解。 步骤1 下载一个分类模型(如AlexNet) 步骤2 对模型进行微调
步骤3 特征提取:
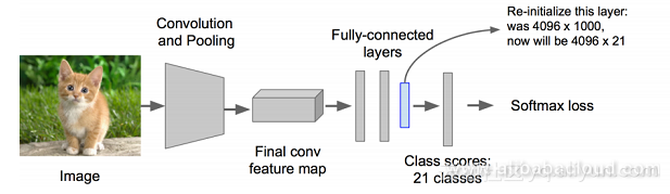
步骤4
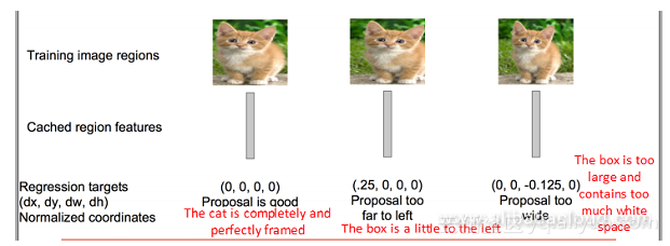
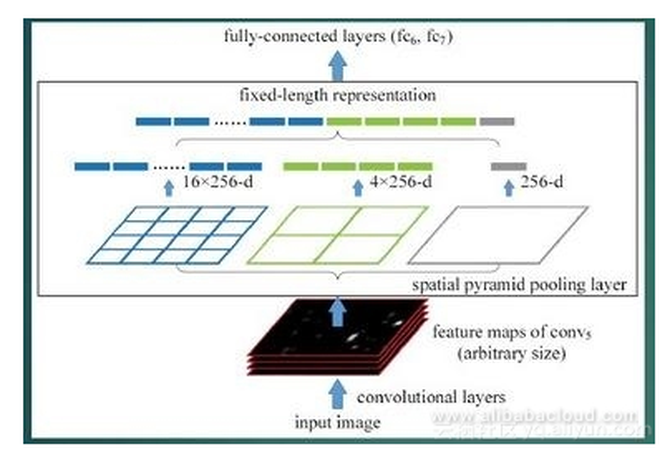
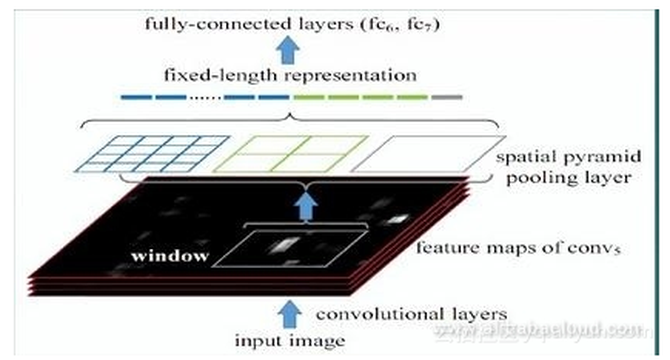
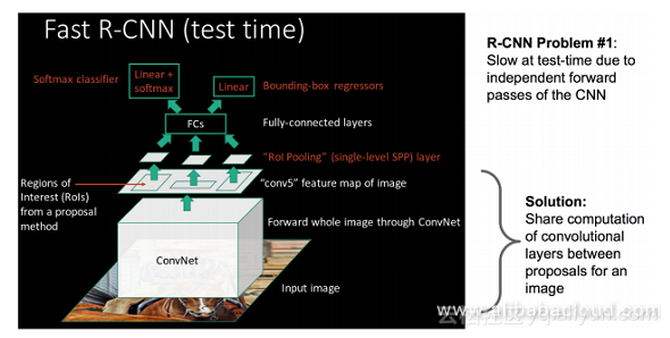
步骤5 使用回归器对候选方框的位置进行仔细校正。对于每一个分类,都需要训练一个线性回归模型,用以判断这个方框是否足够匹配。 空间金字塔池化(SPP:Spatial Pyramid Pooling)概念的提出对R-CNN的发展有着非凡的意义。在此我们会对SPP进行简明的介绍。 SPP有两个特征: 1. 结合空间金字塔法,实现CNN的多尺度输入 2. 只对原始图像提取一次卷积特征 在R-CNN中,每个候选框会将其尺寸调至统一,然后分别作为CNN的输入,但这样的做法降低了效率。SPP Net针对这个缺点做了相应的优化:只对原始图像进行一次卷积操作,得到特征图,然后找到每个候选方框在特征图上的映射,然后将该映射作为卷积特征输入SPP层。这种优化方法节约了大量的计算时间,相比 R-CNN快上百倍。 Fast R-CNN SPP Net非常实用,有学者就在R-CNN的基础上结合SPP Net,提出Fast R-CNN,进一步提升了性能。 R-CNN与Fast R-CNN有什么区别呢? 首先,让我们来看看R-CNN的不足之处。尽管它在提取潜在边框作为输入时,使用了选择性搜索以及其它处理方法,但是R-CNN在运算速度上仍然遇到了瓶颈。这是由于计算机在对所有区域进行特征提取时会进行大量的重复计算。 为了解决这个问题,研究学者提出了Fast R-CNN。 在Fast R-CNN中,有一个被称为ROI Pooling的单层SPP网络层。该网络层能够将不同尺寸的输入映射为一系列固定尺度的特征向量,正如我们所知,conv,pooling,relu以及一些其它操作并不需要固定尺度的输入。因此,当我们在原始图片上执行这些操作后,由于输入图片的尺寸不同,得到的特征图尺寸也不一样,不能将它们直接连接到一个全连接层上进行分类,但是我们可以在其中加入ROI Pooling层,以一个固定尺度的特征来表示每个区域,再通过softmax进行分类。 此外,前面所讲的R-CNN需要先有一个proposal,再输入到CNN中进行特征提取,之后采用SVM进行分类,最后进行边框回归。但是在Fast R-CNN模型中,作者将边框回归引入神经网络,并将其与区域分类合并,形成一个多任务模型。 实验证明,这两个任务能够共享卷积特征。Fast R-CNN的一个额外贡献是使Region Proposal+CNN这一框架得以运用,同时让人们看到进行多类检测的同时仍保证精度是能够实现的。 R-CNN总结:
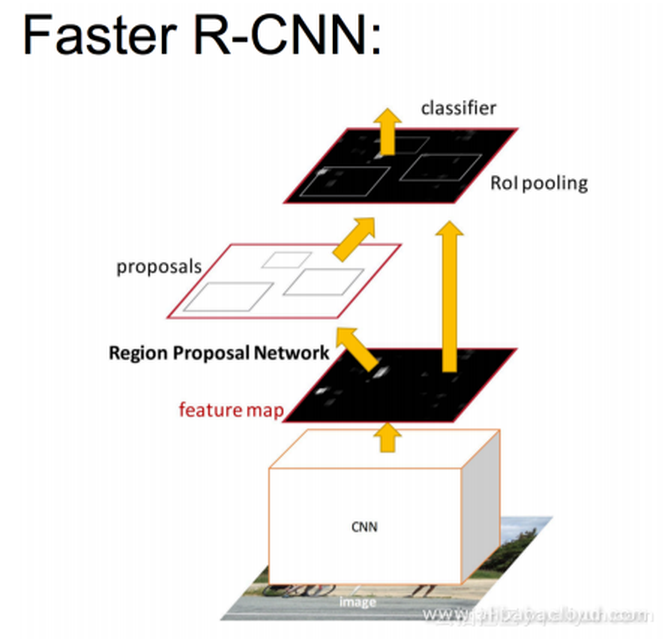
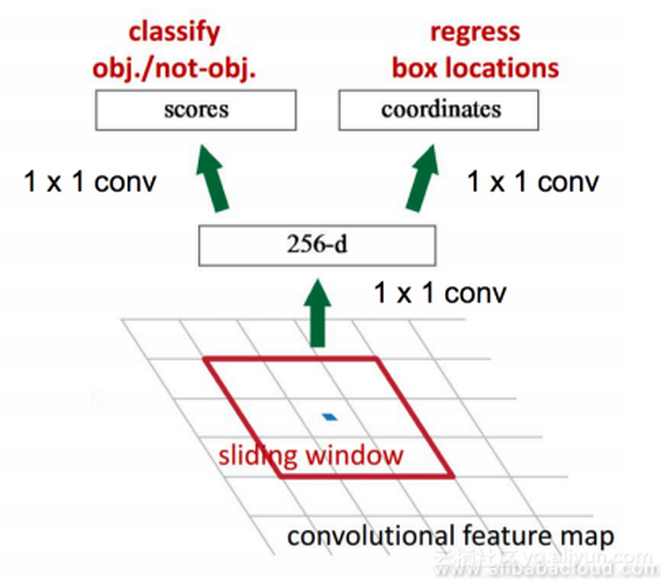
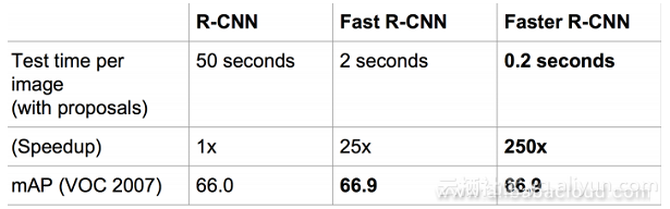
性能的提升也十分明显: Faster R-CNN 毫无疑问,Fast R-CNN与传统的CNN相比,在性能上有了大幅提升。但Fast R-CNN的一个主要问题在于它使用选择性搜索去找所有的候选方框,这是非常耗时的。 是否有更加高效的方法去找出所有的候选方框呢? 解决办法:增加一个可以对边缘进行提取的神经网络。换句话说,利用神经网络去寻找所有的候选方框。能够实现这种操作的神经网络叫做区域生成网络(RPN:Region Proposal Network)。 让我们看看RPN有哪些提升:
RPN总结:
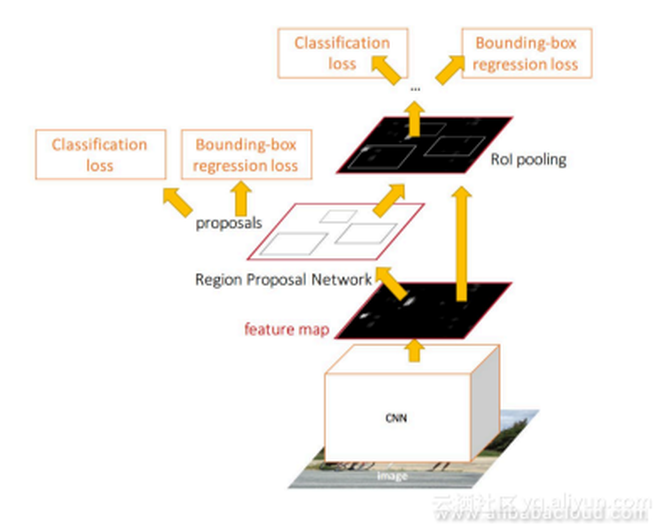
四种损失函数:
速度比较 Faster R-CNN的贡献在于它设计了一个RPN网络对候选区域进行提取,此步骤代替了耗时过多的选择性搜索,使速度得到大幅提升。 总结总的来说,从R-CNN,SPP-NET,Fast R-CNN到R-CNN,基于深度学习进行目标检测的步骤得到了简化,精度得到了提高,速度得到了提升。可以说,基于区域生成的系列R-CNN目标检测算法在目标检测领域已经成为最主要的分支。 本文由北邮 @爱可可-爱生活 老师推荐, 阿里云云栖社区 组织翻译。 文章原标题《From R-CNN to Faster R-CNN: The Evolution of Object Detection Technology》,作者:Leona Zhang,译者:Elaine,审校:袁虎。 文章为简译,更为详细的内容,请查看 原文 (编辑:温州站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |