分布式之抉择分布式锁――多个方位比较
|
为了redis的高可用,一般都会给redis的节点挂一个slave,然后采用哨兵模式进行主备切换。但由于Redis的主从复制(replication)是异步的,这可能会出现在数据同步过程中,master宕机,slave来不及同步数据就被选为master,从而数据丢失。具体流程如下所示: ・(1)客户端1从Master获取了锁。 ・(2)Master宕机了,存储锁的key还没有来得及同步到Slave上。 ・(3)Slave升级为Master。 ・(4)客户端2从新的Master获取到了对应同一个资源的锁。 为了应对这个情形, redis的作者antirez提出了RedLock算法,步骤如下(该流程出自官方文档),假设我们有N个master节点(官方文档里将N设置成5,其实大等于3就行) ・(1)获取当前时间(单位是毫秒)。 ・(2)轮流用相同的key和随机值在N个节点上请求锁,在这一步里,客户端在每个master上请求锁时,会有一个和总的锁释放时间相比小的多的超时时间。比如如果锁自动释放时间是10秒钟,那每个节点锁请求的超时时间可能是5-50毫秒的范围,这个可以防止一个客户端在某个宕掉的master节点上阻塞过长时间,如果一个master节点不可用了,我们应该尽快尝试下一个master节点。 ・(3)客户端计算第二步中获取锁所花的时间,只有当客户端在大多数master节点上成功获取了锁(在这里是3个),而且总共消耗的时间不超过锁释放时间,这个锁就认为是获取成功了。 ・(4)如果锁获取成功了,那现在锁自动释放时间就是最初的锁释放时间减去之前获取锁所消耗的时间。 ・(5)如果锁获取失败了,不管是因为获取成功的锁不超过一半(N/2+1)还是因为总消耗时间超过了锁释放时间,客户端都会到每个master节点上释放锁,即便是那些他认为没有获取成功的锁。 分析:RedLock算法细想一下还存在下面的问题 节点崩溃重启,会出现多个客户端持有锁 假设一共有5个Redis节点:A, B, C, D, E。设想发生了如下的事件序列: (1)客户端1成功锁住了A, B, C,获取锁成功(但D和E没有锁住)。 (2)节点C崩溃重启了,但客户端1在C上加的锁没有持久化下来,丢失了。 (3)节点C重启后,客户端2锁住了C, D, E,获取锁成功。这样,客户端1和客户端2同时获得了锁(针对同一资源)。 为了应对节点重启引发的锁失效问题,redis的作者antirez提出了延迟重启的概念,即一个节点崩溃后,先不立即重启它,而是等待一段时间再重启,等待的时间大于锁的有效时间。采用这种方式,这个节点在重启前所参与的锁都会过期,它在重启后就不会对现有的锁造成影响。这其实也是通过人为补偿措施,降低不一致发生的概率。 时间跳跃问题 (1)假设一共有5个Redis节点:A, B, C, D, E。设想发生了如下的事件序列: (2)客户端1从Redis节点A, B, C成功获取了锁(多数节点)。由于网络问题,与D和E通信失败。 (3)节点C上的时钟发生了向前跳跃,导致它上面维护的锁快速过期。 客户端2从Redis节点C, D, E成功获取了同一个资源的锁(多数节点)。 客户端1和客户端2现在都认为自己持有了锁。 为了应对始终跳跃引发的锁失效问题,redis的作者antirez提出了应该禁止人为修改系统时间,使用一个不会进行“跳跃”式调整系统时钟的ntpd程序。这也是通过人为补偿措施,降低不一致发生的概率。 超时导致锁失效问题 RedLock算法并没有解决,操作共享资源超时,导致锁失效的问题。回忆一下RedLock算法的过程,如下图所示
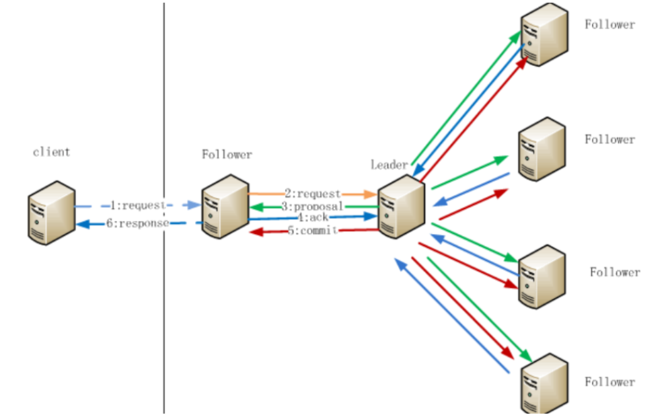
如图所示,我们将其分为上下两个部分。对于上半部分框图里的步骤来说,无论因为什么原因发生了延迟,RedLock算法都能处理,客户端不会拿到一个它认为有效,实际却失效的锁。然而,对于下半部分框图里的步骤来说,如果发生了延迟导致锁失效,都有可能使得客户端2拿到锁。因此,RedLock算法并没有解决该问题。 (2)zookpeer zookpeer在集群部署中,zookpeer节点数量一般是奇数,且一定大等于3。我们先回忆一下,zookpeer的写数据的原理 如图所示,这张图懒得画,直接搬其他文章的了。
那么写数据流程步骤如下 1.在Client向Follwer发出一个写的请求 2.Follwer把请求发送给Leader 3.Leader接收到以后开始发起投票并通知Follwer进行投票 4.Follwer把投票结果发送给Leader,只要半数以上返回了ACK信息,就认为通过 5.Leader将结果汇总后如果需要写入,则开始写入同时把写入操作通知给Leader,然后commit; 6.Follwer把请求结果返回给Client 还有一点,zookpeer采取的是全局串行化操作 OK,现在开始分析 集群同步 client给Follwer写数据,可是Follwer却宕机了,会出现数据不一致问题么?不可能,这种时候,client建立节点失败,根本获取不到锁。client给Follwer写数据,Follwer将请求转发给Leader,Leader宕机了,会出现不一致的问题么?不可能,这种时候,zookpeer会选取新的leader,继续上面的提到的写流程。 总之,采用zookpeer作为分布式锁,你要么就获取不到锁,一旦获取到了,必定节点的数据是一致的,不会出现redis那种异步同步导致数据丢失的问题。 时间跳跃问题 不依赖全局时间,怎么会存在这种问题超时导致锁失效问题不依赖有效时间,怎么会存在这种问题 第三回合,锁的其他特性比较 (1)redis的读写性能比zookpeer强太多,如果在高并发场景中,使用zookpeer作为分布式锁,那么会出现获取锁失败的情况,存在性能瓶颈。 (2)zookpeer可以实现读写锁,redis不行。 (3)ZooKeeper的watch机制,客户端试图创建znode的时候,发现它已经存在了,这时候创建失败,那么进入一种等待状态,当znode节点被删除的时候,ZooKeeper通过watch机制通知它,这样它就可以继续完成创建操作(获取锁)。这可以让分布式锁在客户端用起来就像一个本地的锁一样:加锁失败就阻塞住,直到获取到锁为止。这套机制,redis无法实现 总结 (编辑:温州站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |