分享一个Python中机器学习的特征选择工具
|
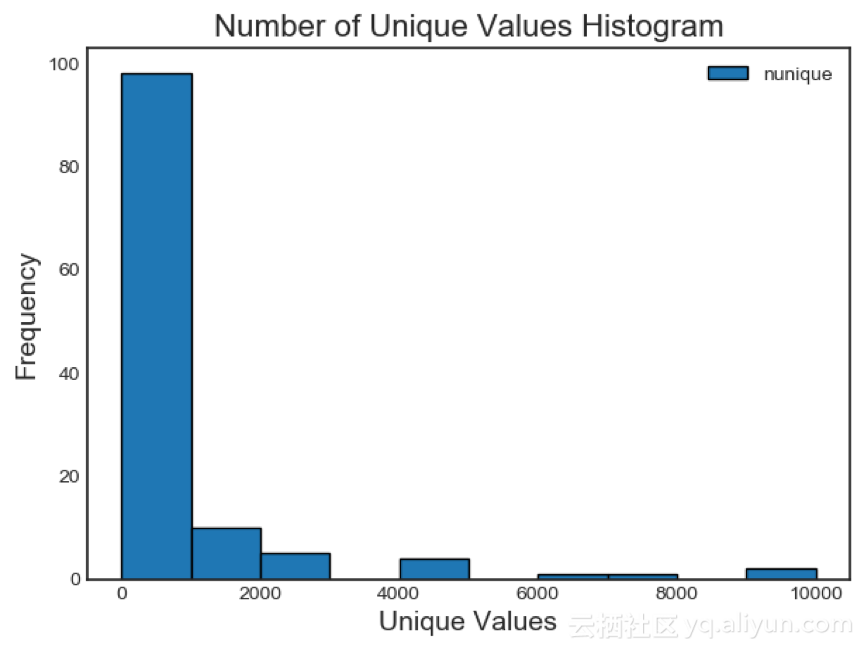
基于特征重要性的方法最适合用来对树型结构模型进行预测。基于重要性的方法是随机的,也是一种黑盒方法,因为模型判定特征是否相关并不透明的。所以在使用基于特征重要性的方法时,应多次运行以查看结果如何变化,并尽可能创建多个具有不同参数的数据集以进行测试! 唯一值特征 最唯一值特征选择法是相当基本的:查找有唯一值的列。只有一个唯一值的特征对于机器学习来说是无用的,因为这个特征的方差为零。例如,只有一个值的特征不能作为树型结构模型的节点(因为该特征不能再分组了)。 绘制各个区间唯一值数量的直方图: fs.plot_unique()
需要记住的一点是:默认在计算Pandas 中唯一值之前,NaNs会被删除。 删除特征 确定了要删除特征后,有两个选择可以删除它们。所有要删除的特征都存储在FeatureSelector的ops属性中,可以根据出现的列表手动删除特征。另一种选择是使用remove内置函数。 使用remove函数删除特征时需传入methods。如果想要使用所有的实现方法,只需传入methods = 'all'。 # Remove the features from all methods (returns a df) train_removed = fs.remove(methods = 'all') ['missing', 'single_unique', 'collinear', 'zero_importance', 'low_importance'] methods have been run Removed 140 features. 该方法删除特征后返回一个dataframe,在机器学习过程中创建的one-hot编码特征也被删除: train_removed_all = fs.remove(methods = 'all', keep_one_hot=False) Removed 187 features including one-hot features. 在开始操作之前先检查要删除的特征!原始数据集存储在FeatureSelector的data属性中作为备份! 结论 在训练机器学习模型之前,特征选择器类实现了一些常见的删除特征的操作。它具有选择要删除特征和绘图的功能。类内方法可以单独运行,也可以为实现高效的工作流而同时运行。 Missing方法, collinear方法和single_unique方法都是具有确定性的,而基于特征重要性的方法会随着每次运行而改变。像机器学习一样,特征选择很大程度上是经验主义。测试多组数据才能得到最佳结果,所以最好多尝试几次。特征选择器提供了一种快速评估特征选择参数的方法。 本文由阿里云云栖社区组织翻译。 文章原标题《a-feature-selection-tool-for-machine-learning-in-python》 作者: William Koehrsen译者:吴兆青,审校:袁虎。 文章为简译,更为详细的内容,请查看原文文章。 (编辑:温州站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |