知识分享:Oracle的三种高可用集群方案
|
在 Oracle9i 之前,RAC 称为 OPS(Oracle Parallel Server)。RAC 与 OPS 之间的一个较大区别是,RAC 采用了Cache Fusion(高缓存合并)技术,节点已经取出的数据块更新后没有写入磁盘前,可以被另外一个节点更新,然后以最后的版本写入磁盘。在 OPS 中,节点间的数据请求需要先将数据写入磁盘,然后发出请求的节点才可以读取该数据。使用 Cache Fusion 时,RAC 的各个节点间数据缓冲区通过高速、低延迟的内部网络进行数据块的传输。下图是一个典型的 RAC 对外服务的示意图,一个 Oracle RAC Cluster 包含了如下的部分
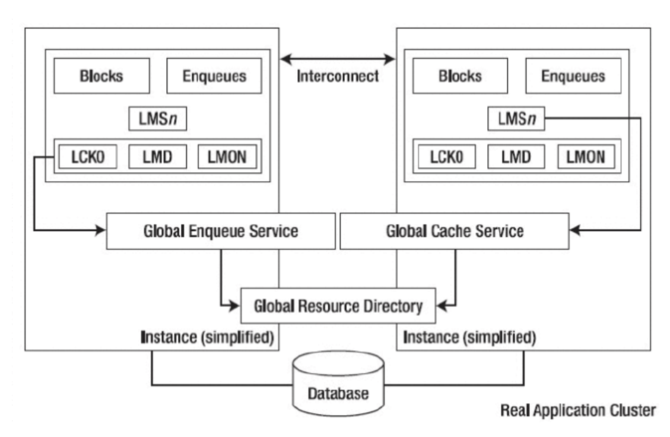
集群的节点(Cluster node)――2 个到 N 个节点或者主机运行 Oracle Database Server。 私有网络(Network Interconnect)――RAC 之间需要一个高速互联的私有网络来处理通信和 Cache Fusion。 共享存储(shared Storage)――RAC 需要共享存储设备让所有的节点都可以访问数据文件。 对外服务的网络(Production Network)――RAC 对外服务的网络。客户端和应用都通过这个网络来访问。 RAC 后台进程 Oracle RAC 有一些自己独特的后台进程,在单一实例中不发挥配置作用。如下图所示,定义了一些 RAC 运行的后台进程。这些后台进程的功能描述如下。
(1)LMS(Global cache service processes 全局缓存服务进程)进程主要用来管理集群内数据块的访问,并在不同实例的 Buffer Cache 中传输数据块镜像。直接从控制的实例的缓存复制数据块,然后发送一个副本到请求的实例上。并保证在所有实例的 Buffer Cache 中一个数据块的镜像只能出现一次。LMS 进程靠着在实例中传递消息来协调数据块的访问,当一个实例请求数据块时,该实例的 LMD 进程发出一个数据块资源的请求,该请求指向主数据块的实例的 LMD 进程,主实例的 LMD 进程和正在使用的实例的 LMD 进程释放该资源,这时拥有该资源的实例的 LMS 进程会创建一个数据块镜像的一致性读然后把该数据块传递到请求该资源的实例的BUFFER CACHE 中。LMS 进程保证了在每一时刻只能允许一个实例去更新数据块,并负责保持该数据块的镜像记录(包含更新数据块的状态 FLAG)。RAC 提供了 10 个 LMS 进程(0~9),该进程数量随着节点间的消息传递的数据的增加而增加。(2)LMON(Lock Monitor Process,锁监控进程)是全局队列服务监控器,各个实例的 LMON 进程会定期通信,以检查集群中各个节点的健康状况,当某个节点出现故障时,负责集群重构、GRD 恢复等操作,它提供的服务叫做 Cluster Group Service(CGS)。 LMON 主要借助两种心跳机制来完成健康检查。 (一) 节点间的网络心跳(Network Heartbeat):可以想象成节点间定时的发送 ping 包检测节点状态,如果能在规定时间内收到回应,就认为对方状态正常。 (二) 通过控制文件的磁盘心跳(controlfile heartbeat):每个节点的 CKPT 进程每隔 3 秒钟更新一次控制文件的数据块,这个数据块叫做 Checkpoint Progress Record,控制文件是共享的,所以实例间可以互相检查对方是否及时更新来判断。 (三) LMD(the global enqueue service daemon,锁管理守护进程)是一个后台进程,也被称为全局的队列服务守护进程,因为负责对资源的管理要求来控制访问块和全局队列。在每一个实例的内部,LMD 进程管理输入的远程资源请求(即来自集群中其他实例的锁请求)。此外,它还负责死锁检查和监控转换超时。 (四) LCK(the lock process,锁进程)管理非缓存融合,锁请求是本地的资源请求。LCK 进程管理共享资源的实例的资源请求和跨实例调用操作。在恢复过程中它建立一个无效锁元素的列表,并验证锁的元素。由于处理过程中的 LMS 锁管理的首要职能,只有一个单一的 LCK 进程存在每个实例中。 (五) DIAG(the diagnosability daemon,诊断守护进程)负责捕获 RAC 环境中进程失败的相关信息。并将跟踪信息写出用于失败分析,DIAG 产生的信息在与 Oracle Support 技术合作来寻找导致失败的原因方面是非常有用的。每个实例仅需要一个 DIAG 进程。 (六) GSD(the global service daemon,全局服务进程)与 RAC 的管理工具 dbca、srvctl、oem 进行交互,用来完成实例的启动关闭等管理事务。为了保证这些管理工具运行正常必须在所有的节点上先start gsd,并且一个 GSD 进程支持在一个节点的多个 rac.gsd 进程位ORACLEHOME/bin目录下,其log文件为ORACLEHOME/bin目录下,其log文件为ORACLE_HOME/srvm/log/gsdaemon.log。GCS 和 GES 两个进程负责通过全局资源目录(Global Resource Directory GRD)维护每个数据的文件和缓存块的状态信息。当某个实例访问数据并缓存了数据之后,集群中的其他实例也会获得一个对应的块镜像,这样其他实例在访问这些数据是就不需要再去读盘了,而是直接读取 SGA 中的缓存。GRD 存在于每个活动的 instance 的内存结构中,这个特点造成 RAC 环境的 SGA 相对于单实例数据库系统的 SGA 要大。其他的进程和内存结构都跟单实例数据库差别不大。 RAC 共享存储 RAC 需要有共享存储,独立于实例之外的信息,如上面提到的ocr 和 votedisk 以及数据文件都存放在这个共享存储里的。有OCFS、OCFS2、RAW、NFS、ASM 等这样的一些存储方式。OCFS(Oracle Cluster File System) 和 OCFS2 就是一个文件系统而已,和 NFS 一样,提供一种集群环境中的共享存储的文件系统。RAW 裸设备也是一种存储方式,是 oracle11g 之前的版本中 RAC 支持的存储方式,在 Oralce9i 之前,OPS/RAC的支持只能使用这样的方式,也就是把共享存储映射到 RAW Device,然后把 Oracle 需要的数据选择 RAW device存储,但是 RAW 相对于文件系统来说不直观,不便于管理,而且 RAW Device 有数量的限制,RAW 显然需要有新的方案来代替,这样就有了 OCFS 这样的文件系统。当然,这只是 Oracle 自己的实现的集文件系统而已,还有其他厂商提供的文件系统可以作为存储的选择方案。ASM 只是数据库存储的方案而已,并不是 cluster 的方案,所以这里 ASM 应该是区别于 RAW 和 OCFS/OCFS2同一级别的概念,RAW 和 OCFS/OCFS2 不仅可以作为数据库存储的方案,同时也可以作为 Clusterware 里的存储方案,是 CRS 里需要的 storage,而 ASM 仅作为数据库的存储而已,严格来说仅是 RAC 中的一个节点应用(nodeapps)。ASM 对于 clusterware 安装时需要的 ocr 和 votedisk 这两项还不支持,毕竟 ASM 本身就需要一个实例,而 CRS 是完全在架构之外的,这也就是为什么使用了 ASM 的方案,却总还要加上 OCFS/OCFS2 和 RAW 其中的一个原因。各种 RAC 共享存储方式的对比如下: 集群文件系统――支持 windows 和 Linux 的 OCFS/OCFS2 (编辑:温州站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |