阿里 7 亿元收购 Apache Flink 商业公司 DataArtisans
|
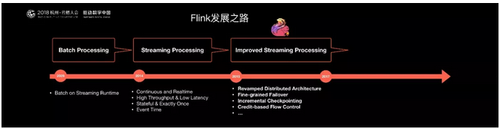
什么是状态?例如开发一套流计算的系统或者任务做数据处理,可能经常要对数据进行统计,如Sum,Count,Min,Max,这些值是需要存储的。因为要不断更新,这些值或者变量就可以理解为一种状态。如果数据源是在读取Kafka,RocketMQ,可能要记录读取到什么位置,并记录Offset,这些Offset变量都是要计算的状态。 Flink提供了内置的状态管理,可以把这些状态存储在Flink内部,而不需要把它存储在外部系统。这样做的好处是第一降低了计算引擎对外部系统的依赖以及部署,使运维更加简单;第二,对性能带来了极大的提升:如果通过外部去访问,如Redis,HBase它一定是通过网络及RPC。如果通过Flink内部去访问,它只通过自身的进程去访问这些变量。同时Flink会定期将这些状态做Checkpoint持久化,把Checkpoint存储到一个分布式的持久化系统中,比如HDFS。这样的话,当Flink的任务出现任何故障时,它都会从最近的一次Checkpoint将整个流的状态进行恢复,然后继续运行它的流处理。对用户没有任何数据上的影响。 Flink是如何做到在Checkpoint恢复过程中没有任何数据的丢失和数据的冗余?来保证精准计算的? 这其中原因是Flink利用了一套非常经典的Chandy-Lamport算法,它的核心思想是把这个流计算看成一个流式的拓扑,定期从这个拓扑的头部Source点开始插入特殊的Barries,从上游开始不断的向下游广播这个Barries。每一个节点收到所有的Barries,会将State做一次Snapshot,当每个节点都做完Snapshot之后,整个拓扑就算完整的做完了一次Checkpoint。接下来不管出现任何故障,都会从最近的Checkpoint进行恢复。 Flink利用这套经典的算法,保证了强一致性的语义。这也是Flink与其他无状态流计算引擎的核心区别。 下面介绍Flink是如何解决乱序问题的。比如星球大战的播放顺序,如果按照上映的时间观看,可能会发现故事在跳跃。 在流计算中,与这个例子是非常类似的。所有消息到来的时间,和它真正发生在源头,在线系统Log当中的时间是不一致的。在流处理当中,希望是按消息真正发生在源头的顺序进行处理,不希望是真正到达程序里的时间来处理。Flink提供了Event Time和WaterMark的一些先进技术来解决乱序的问题。使得用户可以有序的处理这个消息。这是Flink一个很重要的特点。 接下来要介绍的是Flink启动时的核心理念和核心概念,这是Flink发展的第一个阶段;第二个阶段时间是2015年和2017年,这个阶段也是Flink发展以及阿里巴巴介入的时间。故事源于2015年年中,我们在搜索事业部的一次调研。当时阿里有自己的批处理技术和流计算技术,有自研的,也有开源的。但是,为了思考下一代大数据引擎的方向以及未来趋势,我们做了很多新技术的调研。 结合大量调研结果,我们最后得出的结论是:解决通用大数据计算需求,批流融合的计算引擎,才是大数据技术的发展方向,并且最终我们选择了Flink。 但2015年的Flink还不够成熟,不管是规模还是稳定性尚未经历实践。最后我们决定在阿里内部建立一个Flink分支,对Flink做大量的修改和完善,让其适应阿里巴巴这种超大规模的业务场景。在这个过程当中,我们团队不仅对Flink在性能和稳定性上做出了很多改进和优化,同时在核心架构和功能上也进行了大量创新和改进,并将其贡献给社区,例如:Flink新的分布式架构,增量Checkpoint机制,基于Credit-based的网络流控机制和Streaming SQL等。 Flink的未来方向 首先,阿里巴巴还是要立足于Flink的本质,去做一个全能的统一大数据计算引擎。将它在生态和场景上进行落地。目前Flink已经是一个主流的流计算引擎,很多互联网公司已经达成了共识:Flink是大数据的未来,是最好的流计算引擎。下一步很重要的工作是让Flink在批计算上有所突破。在更多的场景下落地,成为一种主流的批计算引擎。然后进一步在流和批之间进行无缝的切换,流和批的界限越来越模糊。用Flink,在一个计算中,既可以有流计算,又可以有批计算。 第二个方向就是Flink的生态上有更多语言的支持,不仅仅是Java,Scala语言,甚至是机器学习下用的Python,Go语言。未来我们希望能用更多丰富的语言来开发Flink计算的任务,来描述计算逻辑,并和更多的生态进行对接。 最后不得不说AI,因为现在很多大数据计算的需求和数据量都是在支持很火爆的AI场景,所以在Flink流批生态完善的基础上,将继续往上走,完善上层Flink的Machine Learning算法库,同时Flink往上层也会向成熟的机器学习,深度学习去集成。比如可以做Tensorflow On Flink, 让大数据的ETL数据处理和机器学习的Feature计算和特征计算,训练的计算等进行集成,让开发者能够同时享受到多种生态给大家带来的好处。 (编辑:温州站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |