360海量数据存储 zeppelin设计与实现
|
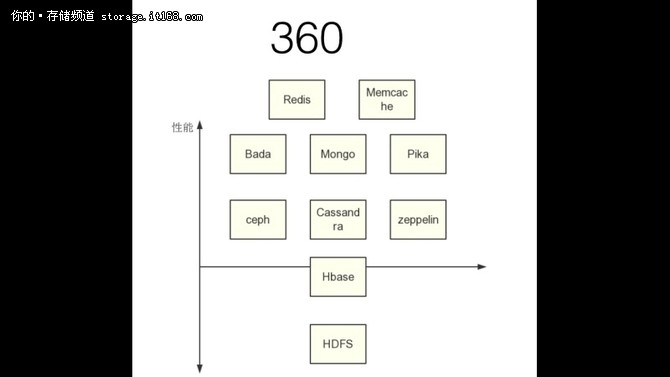
因此其实我们也可以这么说对于这么多接口的实现, 其实后续都会转换成基于key-value 接口实现另一种接口的形式, 因为key-value 接口足够简单, 有了稳定的key-value 存储, 只需要在上层提供不同接口转换成key-value 接口的实现即可. 当然不同的接口实现难度还是不太一样, 比如实现SQL接口, POSIX文件系统接口, 图数据库肯定要比实现一个对象存储的接口要容易很多 所以**zeppelin 定位的是高可用, 高性能, 可定制一致性的key-value 服务**, 上层可以对接各个协议的实现, 目前zeppelin 已经实现支持key-value 接口, 用于线上搜索系统中. 标准的S3 接口实现, 并且用于公司内部存储docker 镜像, 代码发布系统等等 这个是目前360 的存储体系
讲了这么多我对存储的了解, 我们对zeppelin 的定位. 那么接下来聊聊zeppelin 具体的实现
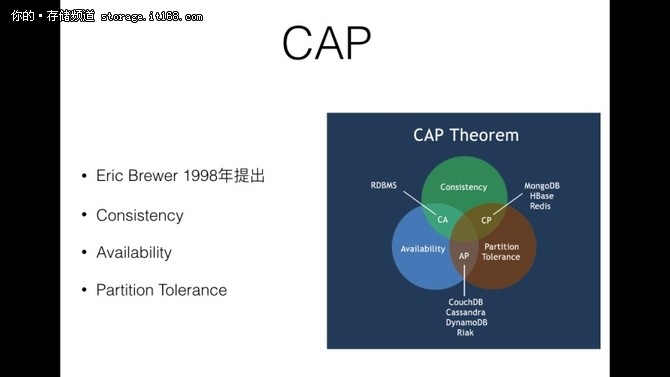
CAP 理论指的是 CAP 并不能同时满足, 而P 是基本都需要满足的, 所以基本都是AP, CP. 但是这里并不是说只能选AP 就没有C, 而是Consistency 的级别不一样, 同样CP 也值得并不是A, 只是A的级别不一样而已
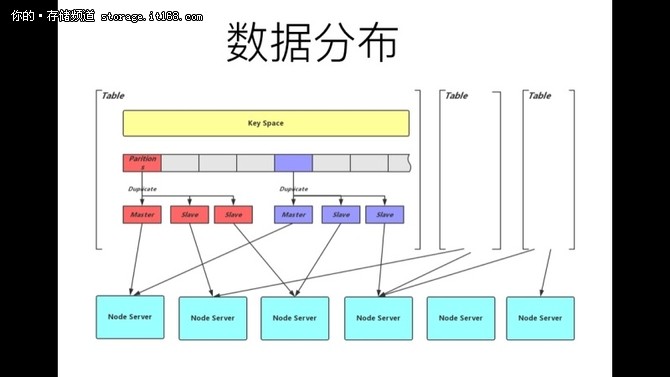
数据分布 * 均匀性(uniformity) * 稳定性(consistency) 所有的分片策略都是在均匀性和稳定性之间的折衷 常见策略 * 一致性Hash * 固定Hash 分片 * Range Hash * crush zeppelin 的选择 固定Hash 分片 1. 实现简单 2. Partition Number > Server Number 可以解决扩展性问题 3. 固定Hash 分片便于运维管理 4. 通过合理设置Hash 函数已经Server 对应的Partition数, 解决均匀性问题
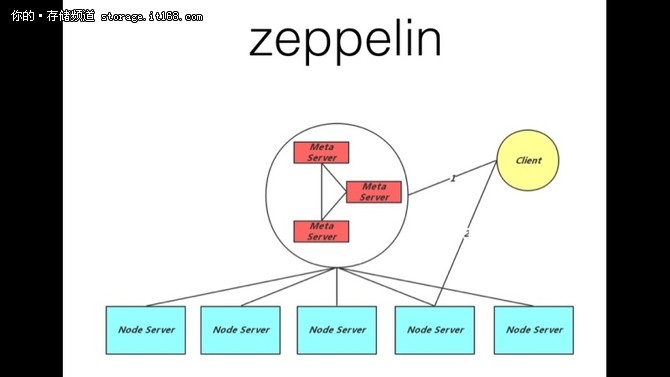
有中心节点的设计. * 为什么这么做? * 目前主流的设计一般是两种 * Bigtable 为代表的, 有MetaServer, DataServer的设计, MetaServer存储元数据信息, DataServer存储实际的数据. 包括 百度的Mola, bigtable, Hbase等等 * Dynamo 为代表的, 对等结构设计. 每一个节点都是一样的结构, 每一个节点都保存了数据的元信息以及数据. 包括 cassandra, Riak 等等 zeppelin 的选择 有中心节点优点是简单, 清晰, 更新及时, 可扩展性强. 缺点是存在单点故障 无中心节点优点是无单点故障, 水平扩展能力强. 缺点是消息传播慢, 限制集群规模等等 因为后续我们会考虑支持zeppelin 到千个节点的规模, 因此无中心节点的设计不一定能够满足我们后期的扩展性, 所以zeppelin 是有中心节点的设计, 那么我们就需要做大量的事情去减少对Meta Server 的压力 zeppelin 选择有中心节点的设计, 但是我们操作大量的优化去尽可能避免中心节点的压力, 同时通过一致性协议来保证元数据更新的强一致 1. Client 缓存大量元信息, 只有Client 出错是才有访问Meta Server 2. 以节点为维度的心跳设计 副本策略 1. Master - Slave 以MongoDB, redis-cluster, bada 为主的, 有主从结构的设计, 那么读写的时候, 客户端访问的都是主副本, 通过binlog/oplog 来将数据同步给从副本 2. Quorum(W+R>N) 以cassandra, dynamo 为主的, 没有主从结构的设计, 读写的时候满足quorum W + R > N, 因此写入的时候写入2个副本成功才能返回. 读的时候需要读副本然后返回最新的. 这里的最新可以是时间戳或者逻辑时间 3. EC (erasure code) EC 其实是一个CPU 换存储的策略, ec 编码主要用于保存偏冷数据, 可以以减少的副本数实现和3副本一样的可用性. ec编码遇到的问题是如果某一个副本挂掉以后, 想要恢复副本的过程必须与其他多个节点进行通信来恢复数据, 会照成大量的网络开销. zeppelin 的选择 目前zeppelin 只实现的Master-Slave 策略, 后续会根据业务场景, 存储成本的需求实现EC, Quorum. 存储引擎
Manos Athanassoulis [**Designing Access Methods: The RUM Conjecture**](http://101.96.8.165/stratos.seas.harvard.edu/files/stratos/files/rum.pdf) RUM 是 写放大, 读放大, 空间放大 之前的权衡 写放大: 写入引擎的数据和实际存储的数据大小比 读放大: 读放大是一次读取需要的IO 次数大小比 空间放大: 实际的数据总量和引擎中存储的数据总量关系大小比
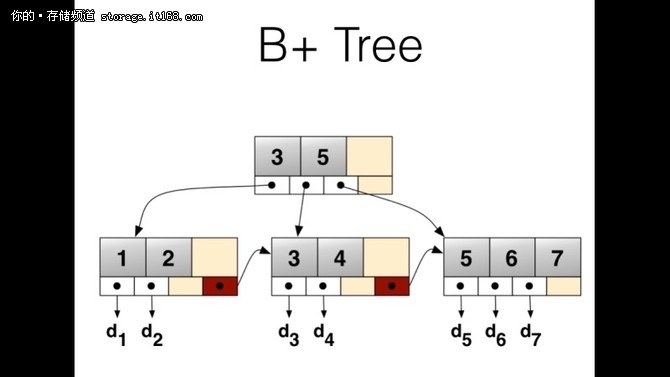
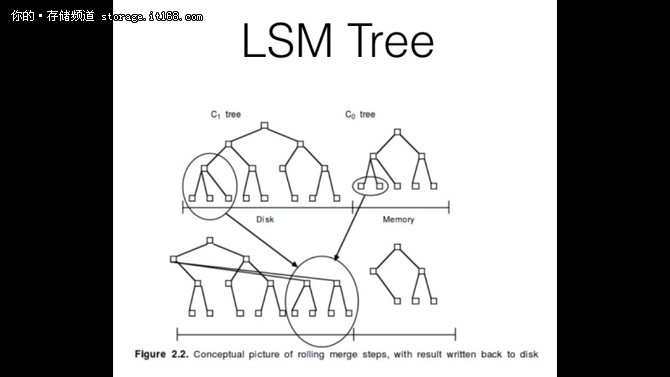
当然这里主要根据DAM 模型(disk access model), 得出结论 当然这里并没有考虑 LSM Tree 里面场景的 bloom filter 等等 这里B+ tree 主要用在 数据库相关, 支持范围查找的操作, 因为B+ Tree 在底下有序数据是连续的 zeppelin 的选择 zeppelin 目前使用的是改过的rocksdb, nemo-rocksdb. nemo-rocksdb 支持TTL, 支持后台定期compaction 等等功能 https://github.com/Qihoo360/nemo-rocksdb 一致性协议 floyd 是c++ 实现的raft 协议, 元信息模块的管理主要通过floyd 来维护.
1. 关于paxos, multi-paxos 的关系 (编辑:温州站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |