360海量数据存储 zeppelin设计与实现
|
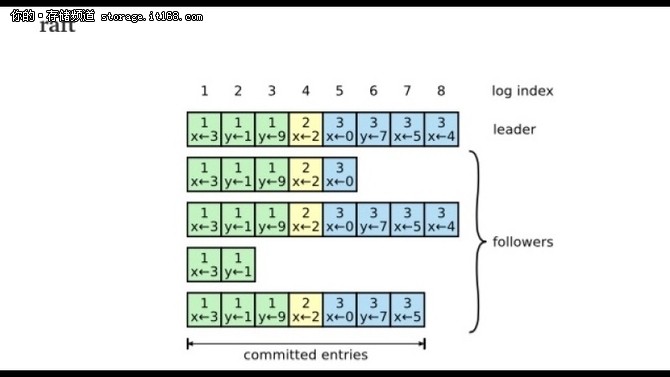
其实paxos 是关于对某一个问题达成一致的一个协议. paxos make simple 花大部分的时间解释的就是这个一个提案的问题, 然后在结尾的Implementing a State Machine 的章节介绍了我们大部分的应用场景是对一堆连续的问题达成一致, 所以最简单的方法就是实现每一个问题独立运行一个Paxos 的过程, 但是这样每一个问题都需要Prepare, Accept 两个阶段才能够完成. 所以我们能不能把这个过程给减少. 那么可以想到的解决方案就是把Prepare 减少, 那么就引入了leader, 引入了leader 就必然有选leader 的过程. 才有了后续的事情, 这里可以看出其实lamport 对multi-paxos 的具体实现其实是并没有细节的指定的, 只是简单提了一下. 所以才有各种不同的multi-paxos 的实现 那么paxos make live 这个文章里面主要讲的是如何使用multi paxos 实现chubby 的过程, 以及实现过程中需要解决的问题, 比如需要解决磁盘冲突, 如何优化读请求, 引入了Epoch number等, 可以看成是对实现multi-paxos 的实践 2. 关于 multi-paxos 和 raft 的关系 从上面可以看出其实我们对比的时候不应该拿paxos 和 raft 对比, 因为paxos 是对于一个问题达成一致的协议, 而raft 本身是对一堆连续的问题达成一致的协议. 所以应该比较的是multi-paxos 和raft 那么multi-paxos 和 raft 的关系是什么呢? raft 是基于对multi paxos 的两个限制形成的 * 发送的请求的是连续的, 也就是说raft 的append 操作必须是连续的. 而paxos 可以并发的. (其实这里并发只是append log 的并发提高, 应用的state machine 还是必须是有序的) * 选主是有限制的, 必须有最新, 最全的日志节点才可以当选. 而multi-paxos 是随意的 所以raft 可以看成是简化版本的multi paxos(这里multi-paxos 因为允许并发的写log, 因此不存在一个最新, 最全的日志节点, 因此只能这么做. 这样带来的麻烦就是选主以后, 需要将主里面没有的log 给补全, 并执行commit 过程) 基于这两个限制, 因此raft 的实现可以更简单, 但是multi-paxos 的并发度理论上是更高的. 可以对比一下multi-paxos 和 raft 可能出现的日志 multi-paxos
raft
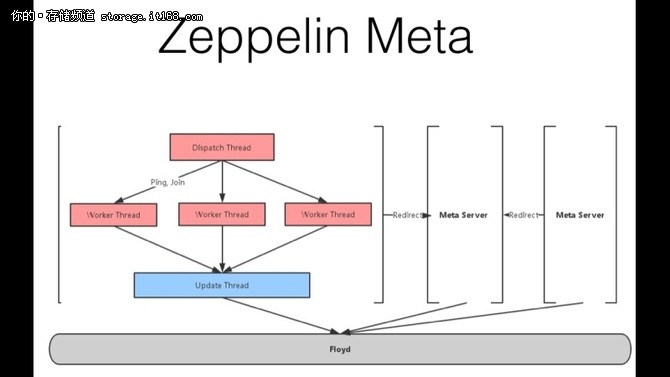
▲ 可以看出, raft 里面follower 的log 一定是leader log 的子集, 而multi-paxos 不做这个保证 3. 关于paxos, multi-paxos, raft 的关系 所以我觉得multi-paxos, raft 都是对一堆连续的问题达成一致的协议, 而paxos 是对一个问题达成一致的协议, 因此multi-paxos, raft 其实都是为了简化paxos 在多个问题上面达成一致的需要的两个阶段, 因此都简化了prepare 阶段, 提出了通过有leader 来简化这个过程. multi-paxos, raft 只是简化不一样, raft 让用户的log 必须是有序, 选主必须是有日志最全的节点, 而multi-paxos 没有这些限制. 因此raft 的实现会更简单. 因此从这个角度来看, Diego Ongaro 实现raft 这个论文实现的初衷应该是达到了, 让大家更容易理解这个paxos 这个东西 zeppelin 的选择 zeppelin MetaServer 一致性是由自己实现的raft 库floyd 来保证. 写入和读取可以通过raft 协议实现强一致, 同时为了性能考虑我们在读取的时候还提供DirtyRead 的接口, floyd 已经在github上面开源, 是用c++实现的raft 协议, 实现的非常的简介明了 https://github.com/Qihoo360/floyd floyd 的压测报告 https://github.com/Qihoo360/floyd/wiki/5-性能测试 整体实现
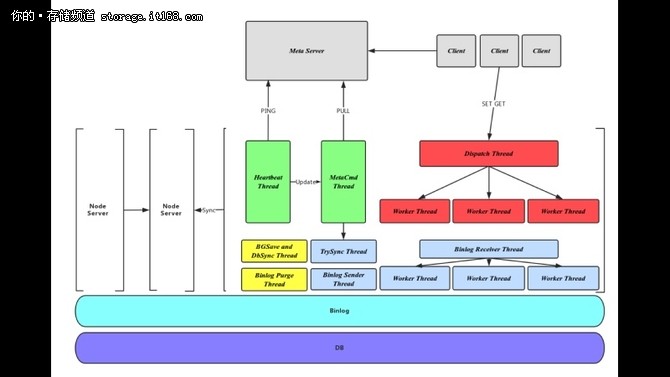
Meta Server 总体结构
Zeppelin自上而下的层次如图所示。 - Network Proxy:负责网络的压包解包,采用Protobuf协议通Meta Server, Client, 及其他Node Server进行交互; - Zeppelin Process:Zeppline主要逻辑处理层,包括分表分片,数据同步,命令处理等; - Binlog:操作日志,同时是同步模块的数据来源; - 存储层:采用Rocksdb进行数据存储。 3. 线程模型
Zeppelin采用多线程的方式进行工作,Zeppline中的所有线程都是与Node绑定的,不会随着Table或Partiiton的个数增加而增加。根据不同线程的任务及交互对象将线程分为三大类: 1,元信息线程,包括Heartbeat Thread及MetaCmd Thread - Heartbeat Thread:负责与Meta Server保持的心跳连接,并通过PING信息感知Meta Server元信息的更新; (编辑:温州站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |

 2. Data Server 总体结构
2. Data Server 总体结构