黄波:AI技术在知乎的应用实践
|
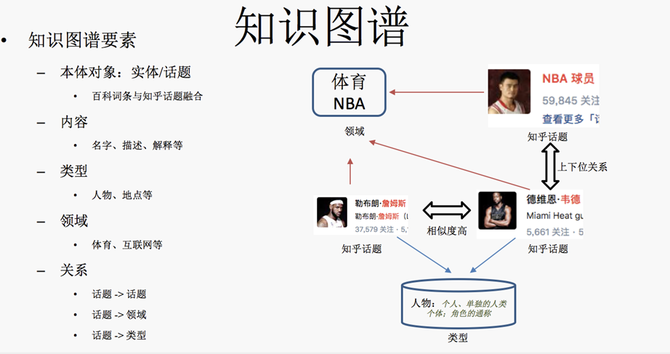
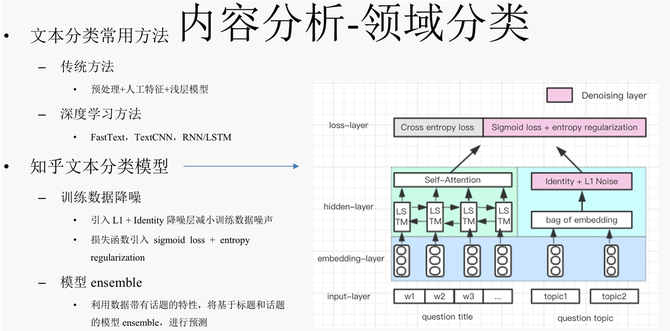
【技术】导语:本文根据知乎AI团队技术负责人黄波于第十届中国系统架构师大会(SACC 2018)的现场演讲《知乎如何利用AI理解内容和用户》内容整理而成。 讲师介绍 黄波,知乎AI团队技术负责人。负责知乎NLP与用户画像相关技术与业务。硕士毕业于北京大学智能科学系,曾在JMLR、ICLR等国际顶级期刊及会议发表多篇学术论文。在加入知乎前,曾任百度自然语言处理部门高级算法工程师,从事智能交互、语义表示、语义标签、内容质量的研发工作,参与了度秘、百度feed流等产品的关键技术突破。 正文: 大家下午好,非常感谢SACC大会的邀请,我今天演讲的主题是AI技术在知乎的应用,内容重点介绍偏底层的相关技术,包括知识图谱、内容分析与用户分析。最后会简单介绍这三块技术在相关业务线的应用。 一、知识图谱的构建与应用 我们先来看一下知识图谱,知识图谱的构建包括三个核心要素:本体、本体属性以及本体间的关系。其构建过程大概分三步:第一步基于互联网上结构化和半结构化数据抽取本体信息,再通过知识融合构建统一的本体库,这里本体通常包括实体、概念、事件等;第二步我们会挖掘本体的属性以及本体间的关系,比如本体“勒布朗 詹姆斯”的类型属性是”人物”、领域属性是”体育“,与本体”德怀恩 韦德“有较强的相似性,与本体”NBA“属于上下位关系等;第三步是知识图谱的表征,我们可以利用离散如 RDF 规则语言和基于神经网络的 embedding 方式来表示知识图谱。 我们在构建知识图谱时主要以知乎话题为核心,将百科词条与话题进行融合构建本体库,并丰富本体的内容信息,包括名字、描述、解释等,同时会挖掘本体相关的属性,例如本体的类型是人物还是地点,以及对应领域属于互联网还是体育。 本体关系的构建分为两种,第一种是话题的上下位关系,上图中可见,韦德的上位话题是NBA球员;另外是话题的相似关系,比如说话题“韦德”和话题“詹姆斯”的相似度就非常高,话题上下位为有向关系,相似关系为无向的。另外也有本体和属性之间的关系,“詹姆斯”对应一级领域为“体育”、二级领域为“NBA”,对应的类型为“人物”。 对于知识图谱的表示,主要有两类方法,一类是离散表示,通过各种规则语言如RDF等描述结构化的知识,离散表示的优点是直观,可解释性强,此外通过规则语言也能很好地支持较为复杂的结构化知识,当然缺点也比较明显,比如离散表示存在的稀疏性问题,可扩展性也相对较差。另一类是近几年比较流行的连续表示,通过神经网络等方法学习结构化知识的 embedding,将结构化知识映射到低位稠密的空间,最大的优点能够很方便被用于各种上层计算,比如作为神经网络模型的输入等,缺点是可解释性没有离散表示强,表示能力也稍微弱一点,对于较复杂的知识结构不能很好地支持。 下面简单介绍知乎知识表示的模型,我们主要围绕话题为核心来做语义表示。下图是一个例子,问题标题是“科比和詹姆斯的区别在哪里?”,相应的会打上相关的多个话题,包括“NBA”、“科比”,“詹姆斯”等。模型输入层包括话题的 embedding 表示,同时加上窗口对应词的embedding,预测目标为窗口的中心词,此外模型预测目标还加了其他两个任务,一个目标是用话题的embedding去预测其对应的领域,另一个是预测其对应的类型。 模型训练完之后,可以将话题“詹姆斯”和其他话题以及所有的词映射到同一个语义空间里。有什么用呢?既然大家都在同一个语义空间里了,基于话题之间的相似度我们可以构造一个话题的相关性图谱,这里有一个相关性图谱的例子,输入给定话题“Facebook”,相关性图谱可以输出 与其相关的话题,例如 “扎克伯格”、“Facebook广告”、“Twitter”等,相关性图谱可以用在用户潜在感兴趣话题推荐,用户兴趣图谱构建等场景。 二、内容分析实践 讲完知识图谱,接下来讲内容分析。什么是内容分析呢?简单来说就是给内容打上各种各样的标签,包括语义层面的一二级领域、话题、实体、关键词等标签。这里有一个例子,关于物理的一个问题――“有哪些看似荒谬的事,却有着合理的物理解释?”,这个问题对应的一级领域是 “自然科学”,二级领域是“物理学”,另外还有粒度更细的话题,包括 “科普”、“物理科普”、“冷知识”等等。在语义维度标签基础上,我们还会打上内容的质量标签,内容质量包括专业性分析和题文相关性分析,专业性分析是通过文本分析模型判断某个回答/文章内容的专业性,并给出判断其专业性程度的打分,题文相关性模型则是给出回答与问题的相关性打分。最后会基于文本分析模型来判断内容的时效性,时效性标签是上层推荐系统很重要的一个特征,比如低时效的优质内容可以一直在推荐系统里流通被用户消费,而如果是高时效性的优质内容则应该短时间加大其分发量,并且过期之后就不能再让它流通了。 关于语义标签,我们由粗到细构建了一个完整的语义标签体系,包括一二级领域领域、话题到实体/关键词等。为什么要做这种多粒度的语义标签?不同应用场景对语义标签粒度需求不一样,另外对不同粒度的语义标签要求也不一样,比如一二级领域我们希望它是一个粒度相对较粗并且尽量完备正交的分类体系,以尽可能保证任何一篇内容都能被分到对应的一二级领域,话题粒度的标签我们希望模型能够高准确度地打上相关话题,类似地,针对实体/关键词,要求模型的准确度比较高,优先保证热门的实体/关键词被召回就可以。 接下来通过具体展开来讲几个模型来介绍我们怎么做内容分析。 内容分析――领域分类 首先是领域分类,当时做的时候面临最大的问题是没有训练数据,在梳理出分类体系后,对应的分类体系没有相应训练数据,短期内通过人工标注也不太现实,那要怎么构建训练数据呢?我们基于知乎数据每个问题都带有相关话题的特点,再结合以话题为核心的知识图谱,构建了一个带噪声的训练数据集。可以看下面这个例子,对于问题“零基础如何学绘画?”,其对应的话题有“绘画”和“自学”,而“绘画”在知识图谱里面所属的一级领域是“艺术”;“自学”所属的一级领域是“教育”。这样的话,这条训练数据就会同时有“艺术”和“教育”这两个类别,但对于这条数据来说教育在这个类别是错的,也就是属于噪声标签。为了降低噪声对模型效果的影响,我们在模型训练时加入了降噪层来进行降噪,同时预测阶段通过 ensemble 模型的方法进行预测。 (编辑:温州站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |