黄波:AI技术在知乎的应用实践
|
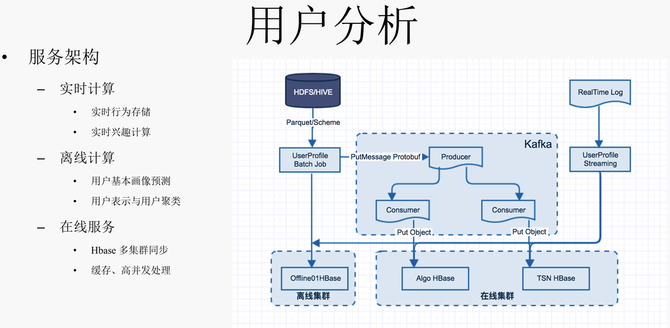
在理解完内容后,我们也需要对用户进行分析,简单来说就是给用户打上各种各样的标签,同时也会对用户社交关系的进行挖掘与建模,比如用户聚类、用户亲密度等。用户分析首先会分析用户的基本属性,像性别年龄以及用户本身的一些登陆地、设备信息等基本属性。然后就是用户兴趣的建模,兴趣计算主要来源于用户对推荐系统的交互行为,我们构建了基于不同粒度语义标签的用户兴趣以灵活支持多种场景,并且时间上也分为长期兴趣和实时短期兴趣,另外也可以根据内容的专业性标签和用户的交互行为判断其对于专业性内容的偏好。这里是一个用户分析的例子,对于“程序员张三”这个用户,我们能获取他的以下画像信息:性别 “男”,兴趣标签有“AI”、“机器学习”,更喜欢看专栏文章这种内容类型的资源,对回答、视频等类型偏好度较弱,另外也更偏好阅读专业性的内容,说明“程序员张三”喜欢在知乎学习计算机和机器学习相关的专业性知识。另一个用户 “运营小丽” 则区别很大,她喜欢看综艺和电视剧相关的讨论,对专业性内容偏好较弱。 用户分析主要依赖于用户和推荐系统的交互行为数据,这里就要求我们能处理好大数据量的离线计算和快速实时计算等大数据相关工作,并且还需提供高并发低延时的在线服务,我们设计了一套完善的离线与在线计算架构,以支撑策略更新和上层业务调用需求。整体架构上分了三大块,第一部分是实时计算,包括用户实时行为存储,用户实时兴趣计算等。第二部分是离线计算,包括模型迭代后的数据批量更新,包括用户基本属性、用户长期兴趣建模、用户聚类等工作。 最后是在线服务这一块,离线计算通常是批量计算的逻辑,比如模型天级别更新去批量预测所有用户的性别或者兴趣标签等,但是离线计算的结果需要“灌到”线上服务的储存供业务方调用,如果直接批量将离线计算的结果导入线上服务会导致线上业务请求失效,在线服务也就崩了。我们在流程上先把批量数据灌到离线集群,再通过kafak消息异步流式地同步到在线集群,以保证线上服务的稳定性。另外也会有缓存请求的相关工作,以支持线上高并发的请求。 下面再介绍下基于spark streaming的用户实时兴趣计算流程。首先我们需要把用户的点击行为、展现以及搜索行为对应的实时数据流打通并进行实时处理,组成一个三元组 <用户、内容、行为类型>。三元组抽取完之后,我们会对内容进行进一步的分析,主要是提取内容对应的领域、话题、关键词等语义标签。为了增加实时处理效率,对问题、文章、回答等内容,可以直接通过 token 到内容画像服务去获取之前已经缓存好的计算结果,而搜索query没法提前算好,需要去调用语义理解模块实时计算获取其对应的标签,比如关键词抽取服务、话题匹配服务等。提取内容标签之后,我们会得到一个 <用户, 标签,行为类型>三元组数据,再以<用户、标签> 进行聚合后,作为最终用户兴趣计算的输入。用户兴趣计算,主要包括新兴趣的叠加,旧兴趣的衰减,策略上会去做一些参数平滑、热门打压等。 最后是用户表示和聚类,用户表示是指通过神经网络或各种embedding方法得到用户在低维空间的embedding 表示,用户embedding表示可以被灵活应用于各种场景。知乎做用户表示有天然的优势,训练数据非常多,有大量的用户社交关系,即用户间的单向和双向关注行为数据,同时用户也会关注话题、问题、专栏、收藏夹等数据,我们把上述数据揉到一起就组成了一个异构图,再利用graph embedding方法来获取每个用户的表示。 四、典型业务应用场景 刚才提到的知识图谱、内容分析以及用户分析,最主要的应用场景是首页信息流推荐。内容分析和用户分析会作为整个推荐系统重要的底层特征,被用作召回、排序阶段。当然召回除了基于内容标签的方式,也有基于协同算法和近几年比较流行的基于神经网络的召回方法。在排序阶段,内容和用户标签也会作为排序模型的输入特征,另外某些标签也可以作为排序模型的目标,比如专业性内容的占比等。 刚才提到,推荐系统在召回阶段不止可以用基于内容标签的方式,也可以用协同和神经网络的方法,那么用标签来做推荐系统召回有什么优点和缺点?优点我这里列了四点,第一个,可解释性强,粒度越细越准确;第二、会越用越准,能积累长期兴趣;第三、可以对各种标签做比例的精准控制,例如强制要求专业性内容的最小占比等;第四,没有内容冷启的问题,任何打上标签的内容都可以被召回;另一方面基于标签召回也存在泛化性较差、标签不能覆盖所有内容等缺点。 除了被用在首页推荐的场景,内容和用户标签也可以应用于数据分析以更好地支持业务和产品决策,典型的例子有:分析专业性内容在生产和消费的分布情况、按领域维度对内容生产和消费进行分析、按人群分析比如大学生对于各种内容的生产/消费分布情况。 最后说下用户表示,它的应用场景很多,典型的场景有受众扩展,简单来说就是可以对种子人群进行扩展;另外就是基于用户表示的用户聚类,还可以进一步对聚类结果进行分析给每一个类打上相应的人群标签,用作人群或者圈子的划分。这里是一个受众扩展的例子,有一些私家课已经有一批点击或者购买的种子人群,现在我们需要找一批用户发优惠券,要保证转化率就要求发给跟这些已经点击或购买用户比较相似的用户, 这里我们就可以基于用户表示计算出与这批种子用户相似的用户。 以上是我今天讲的内容,欢迎大家进一步交流,谢谢! (编辑:温州站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |