黄波:AI技术在知乎的应用实践
|
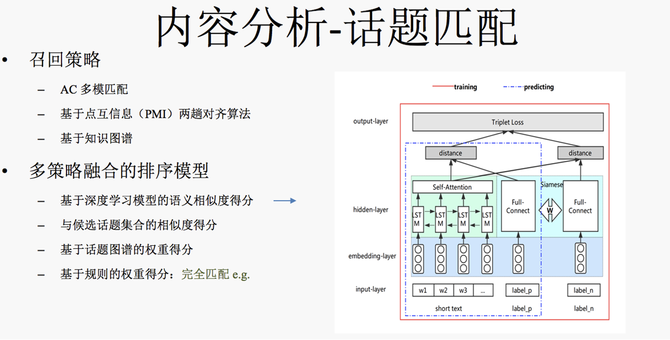
对于传统的文本分类方法,一般是预处理后,结合人工特征和浅层分类器为主的方法。最近几年比较流行基于神经网络的 end2end 文本分类模型,比如说 FastText,TextCNN和RNN/LSTM等文本分类模型。我们选取 LSTM 作为 baseline 模型,但 LSTM 包括上述其他模型都不能很好地降低噪声数据对于模型的影响。 模型展开来讲主要分为两部分,模型左边的输入是问题标题中的词(question title),每个词会对应一个 embedding,词的 embedding 经过一个LSTM层后再过一个Attention 得到问题的表示;右边部分的输入是问题自带的话题(question topic),同样话题也会有对应的embedding层,把话题表示加起来再通过一个 Identity+ L1 Noise 的降噪层得到这个话题降噪后的表示。损失函数层面,我们没有采用常用的交叉熵作为 loss,因为在构建训练数据时,我们发现同一个数据可能会出现多个标签,有时候一个问题确实可以属于多个领域,而有时是噪声数据,采用交叉熵损失较难降低噪声数据的影响。我们采用了 sigmoid 损失加最小熵正则约束的方式来训练模型,sigmoid 损失是多标签任务常用的损失,尽量让模型把多个正例标签都预测为1,但是标签之间没有竞争关系,我们又加上最小熵正则来让标签之间产生竞争以增加模型的降噪能力。在模型预测阶段,我们采用了多模型ensemble的方式,考虑知乎数据带有话题的特点,并且话题都是用户打的,用户打的好处就是可以引入额外知识,当然也会带来一些噪声,我们单独训练了一个基于话题的文本分类模型,会和基于标题的模型ensemble起来进行在线预测。 内容分析――话题匹配 我们再看一下话题匹配。话题匹配是一个文本多标签任务,它的定义是给定一段文本,从给定话题集合中匹配出相应的话题,以自动给问题、文章、Live等进行相关话题标注。这里有个例子,对于问题:“如何评价美剧西部世界”,模型会打上“西部世界”、“西部世界第二季”、“美剧”、“人工智能”等话题,大家平时用知乎提问,问题提出后模型就会推荐出相应的候选集。另外对用户搜索Query模型也能打上相关话题,可以用作搜索特征或用户兴趣画像的沉淀等。 我们在分析时,发现话题匹配这个问题非常难,到底难在哪?难点可以拆成以下三点:第一,话题本身语义粒度的差异特别大,大到领域级别的“娱乐”这种话题,小到“吴亦凡”这种实体级别话题,这种语义粒度差异特别大的情况会让模型很难去学习;第二,话题集合数非常大,大概有10万量级,长尾话题(出现次数小于10)特别多,占比大概80%以上;第三,部分话题之间语义相似度特别高,例如“Python”和“Java”,“插画”和“绘画”这种,通过深度学习模型较难去捕捉这种细微的差异。我们尝试过很多端到端的深度学习方法,包括经典的 FastText、Matching CNN和LSTM+Attention等端到端的方法,这些方法都有一个问题,模型倾向于去预测偏高频 话题,低频、长尾话题的效果较差。 针对上述问题,我们将话题匹配进行了拆解,类似推荐系统一样,包括召回+排序两部分。召回的逻辑是给定候选问题,我们先从标签库里找出数十个最有可能相关的候选话题,在对这候选的数十个话题进行精细的排序打分,最终得到1到5个相关话题。模型效果还算不错,准确是93%,召回是83%。 接来下具体展开讲下召回和排序的策略,召回层分三个策略,第一个是比较简单的AC多模匹配,直接把匹配的话题作为候选集合;第二个比较有意思,我们在经典的点互信息(PMI)算法上做了优化,提出了一个两趟对齐算法的PMI算法,解决了传统PMI不能很好区分 “Python”和“Java”这种经常共现的兄弟节点的问题;最后我们会利用之前构建的知识图谱,把话题的上位话题也作为候选集合召回。 在排序的时候,刚才也有提到单一的端到端模型不能很好地解决话题匹配任务中的问题,我们在深度学习的模型基础上,引入了一些规则策略,最终是一个多策略融合的排序模型。如上图,我们采用了基于LSTM的 pair wise 排序模型。左侧输入是文本的词,词上面接一个 embedding 层,过一个 LSTM层后再过一个Attention层来得到一段文本的表示,右侧分别是正负话题标签,话题上同样接了一个embedding层,再过一个全连接层后得到话题的表示,再将其和该段文本的表示计算相似度,分别计算正负样本与文本的相似度后,最后再计算 pair wise的损失。此外我们还加三个基于规则的排序打分,第一个利用了当前话题与召回阶段得到的数十个话题的相似度得分,思路是正确的话题会倾向于跟召回阶段的大部分话题都比较像,第二个规则我们利用了话题图谱权重来进行打分,最后一个规则比较直观,会对完全匹配的话题进行加权。 内容分析――专业性 最后再讲讲内容的专业性分析,知乎鼓励大家去生产专业性的内容,同时也希望专业内容在知乎得到更多的流通,但难点是机器怎么知道内容是否具有专业性,或者说推荐算法怎么知道内容的专业性程度,通过文本分析模型判断内容专业性是非常必要的。专业性识别的难点主要在于定义比较模糊,针对具体的一条数据很容易判断它的专业性,却很难制定出一个具体的标准,因为不同领域内容判断其是否为专业性的标准差异很大,另一个难点是缺少高质量的训练数据。 专业模型大概分了两个阶段,第一阶段主要利用用户行为,我们分析发现针对专业性内容,用户更倾向于收藏,很直观地思路是,我们利用hits算法对用户创建的收藏夹和收藏夹的内容进行建模,计算出的每个收藏夹权重及对应收藏夹里的内容权重,在此基础上计算出内容的专业性得分。 这个方法优点是准确度非常高,缺点是覆盖相对较低,因为是基于用户行为会有一定的滞后性,没法判断新内容的专业性。在第二个阶段,我们采用了基于文本语义分析的分类模型。这里采用了传统文本分类的人工特征加浅层模型的思路,为什么不用深度学习呢?刚才也提到训练数据获取成本很大,我们大概只有几万条训练数据,而专业性的回答和文章又特别长,直接上深度学习,模型大概率会过拟合。我们的人工特征主要包括两个层面。第一个是文本风格的特征,包括词性,还有标点之类的。另一个是非常重要的语义特征,我们基于全量语料对词进行聚类,并把词的类簇当作专业性模型的一个基本特征,最终专业性的效果准确是84%,召回是60%,应用于首页推荐页也取得了收藏率和点赞率等指标显著提升的正向效果。 三、用户分析实践 (编辑:温州站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |