郭斯杰:重新思考流计算时代的分布式存储
|
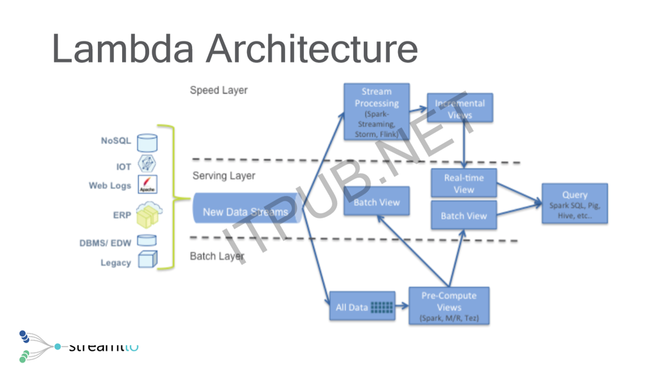
导语:本文根据郭斯杰老师于第十届中国系统架构师大会(SACC 2018)的现场演讲《从文件存储,对象存储到流存储 - 重新思考流计算时代的分布式存储》内容整理而成。 讲师介绍: 郭斯杰,Streamlio的联合创始人之一。Streamlio是一家专注于构建下一代流计算基础设施的初创公司。他也是Apache BookKeeper的PMC主席,Apache Pulsar的PMC成员。在创立Streamlio之前,他是Twitter消息团队的技术负责人。 演讲正文: 大家好,我今天主要分享的是在流计算时代,关于分布式存储的一些思考。自我介绍一下,我是一个开源爱好者,我主要参与的两个开源社区,Pulsar,一个雅虎开源的下一代流数据平台;然后BookKeeper,一个分布式的日志存储系统。在这之前我在Hadoop也做了一些跟Hive、HBase相关的工作。 我目前在硅谷的一家创业公司叫Streamlio,顾名思义,Streamlio其实是由三个单词构成的,就是Stream、ml加IO。所以意图很明显,我们主要是做跟流相关的基础架构,未来我们可能会在基于流的基础架构之上再去做一些ml相关的事情。和流相关的基础机构包括消息中间件、存储、还有计算。在加入Streamlio之前,我在Twitter待了五年,主要负责整个Twitter的消息中间件平台以及数据库复制,包括跨机房复制相关的基础设施。在Twitter之前的话,我是在雅虎做了三年多的时间,然后是华中科大毕业的,后来在中科院计算所读的研究生。 一、背景介绍 我的题目其实是关于“实时时代”,或者说“流计算时代”,对于分布式系统我们应该怎么去考量?我们先看一下,八九十年代,我们最开始存储数据无外乎两种办法,一个是用数据库,另外一种就是以文件的方式进行存储。当你想去存一些数据时,基本上考量的就是这两个事情。后来慢慢演化出了很多分布式数据库、分布式文件系统。随着互联网的到来,数据量越来越大,没办法用传统的技术、本地文件系统、或者是网络文件系统去存大量数据,没有办法在原来的Oracle里面去存数据。因此就演化出了所谓的“神一般的存在”,就是Hadoop。其实Hadoop的整个生态的话是起源于Google的GFS和MapReduce这套系统,基本上现在大家说大数据,开源社区就一个东西,Hadoop,基本上所有互联网公司都会有一套Hadoop的系统。 整个Hadoop的生态,其实是为批量大数据而存在的。随着云时代的到来,像AWS开始把Hadoop放到云上去,作为产品去卖,然后google也会有各种类似的一系列产品,这其实就是为批量以及大数据产生的一套自己的生态,而这个生态的基础,基本上是围绕分布式文件系统去做的存储。 这是批量时代。批时代的到来,很多其实是Google主导,它主要是搜索引擎的应用,对时延的要求性不是很高,可以15分钟跑一个任务,去全网抓一些网页进行索引。 但是随着一些新兴企业的产生,包括比如说像Twitter、Facebook这些社交媒体,会有大量实时产生的数据,就包括用户发的推特,然后你投递的广告以及移动互联网的兴起,会有大量移动端的数据,这个数据的到来就产生了另外一个概念叫做“流”。所谓“流”,它的诞生基本上是因为,虽然我有Hadoop,但是我的时延通常是几分钟甚至小时以上的。 这个是因为在批量时代,它整个计算模型就是一个批处理的模型,所有的数据采集都是通过一个批量的任务,比如说每5分钟、每15分钟写成一堆文件,拿着这个文件提交给计算引擎去处理。随着应用发生变化,这时候你需要处理的响应时间会变得更长。所以在这个情况下,诞生了Storm + Kafka这种特殊的模式。这种模式最开始变得流行,是由Twitter带起来的。因为Twitter整个的产品定位,相当于每个人都是往Twitter上发消息,然后每个人都从Twitter上接受消息,整个的消息的投递、发送都是实时的,整个Twitter的业务是围绕“实时”构建的。 所以在这种情况下,诞生了一个所谓的――基本上大家在做流的时候,不可避免地会认识到的一个东西,叫Storm。因为Storm是一个流计算的框架,但是你的存储本质上还是文件,也就是说我的数据的采集还是以5分钟、15分钟进来。但它不能真正意义上发挥流计算的潜质,所以在这种情况下,你需要的是一个新型的面向流的存储系统。 在那个情况下,基本上大家都是用消息中间件,因此也是在这样的背景下,Kafka与Storm很天然的一个整合,让整个系统变成了流计算的一个事实规范。所以在这种情况下,就衍生出了后面更多的一些流计算框架,比如说Flink,以及Hadoop演化出来的Spark,Spark再继续做Spark Streaming,最后整个计算生态就变得百花争艳。 但是这种情况下,假如我有一个批处理的数据,还有一个流处理的数据,这时候我们会发现在整个公司内部的数据架构,其实变成了两个部分,两个相互隔离的数据孤岛。其中一个数据孤岛是流数据孤岛(Streaming Data Silo),就是说完全是为了Streaming Data去做的一套架构,另外一个数据孤岛是批量数据孤岛(Batch Data Silo),也就是为了批量计算构建的一套独立系统。Streaming Data的话,你通常可以看到你需要一个消息中间件,类似于Kafka或者ACTIVEMQ,然后在上面可以跑流计算的一个引擎。在Batch的话,基本上还HDFS或者其他的分布式文件系统;在云上的话,可能就是对象存储如S3,GCS等类似的对象存储,这上面你可能需要有MapReduce或者是一个类似Hive的数据仓库。但它其实是相互隔离的一个状态。 这个隔离会带来一个问题,你的两个数据其实是相互分离的。分离带来的问题是,我需要学两套API,需要两套集群去存放数据,然后围绕这个生态圈,需要两套工具去管理这些数据。 怎么去解决出现的情况,在Twitter最开始提出的一个架构叫Lambda,意思是说,我有两层,一层是批处理层,就跑我的全量数据,包括MapReduce、包括Spark,但是因为它是批处理,时延是相对比较大的。这时我为了快,再加一个加速层。加速层的是怎么工作的?我的所有数据是通过消息中心进来,基本上是以流的方式进到计算引擎,然后拿一个流处理的计算引擎去做处理,处理完了以后,产生的是一个增量的结果,然后把这两个结果做整合,提供给最终的用户。 (编辑:温州站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |