郭斯杰:重新思考流计算时代的分布式存储
|
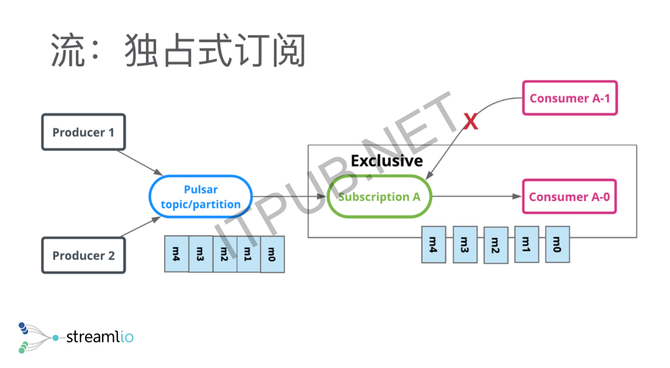
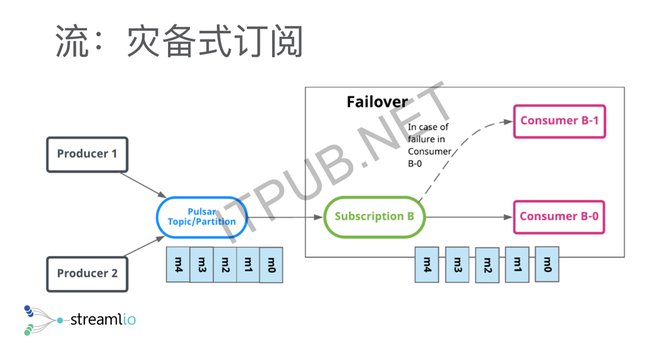
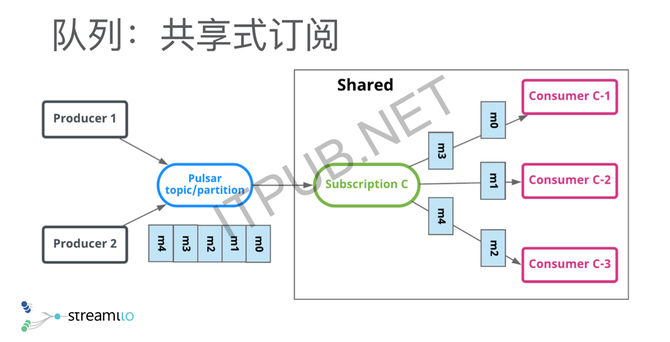
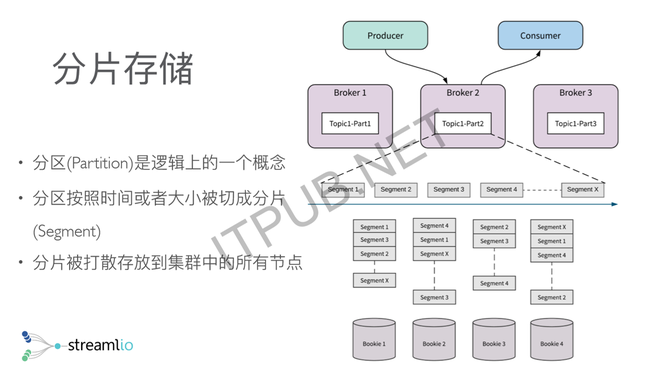
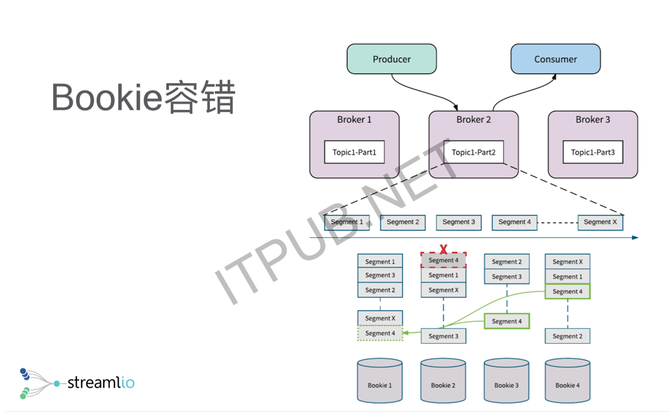
举三个简单的例子,第一个我们叫独占式订阅,就是对于一个topic的一个流,只有一个消费者去消费,那么所有的消费都是顺序的,这时候我可以做很高的吞吐。 另外一种灾备式订阅,其实是独占式的一个延伸,相当于有两个消费者或多个消费者,都想消费这个topic,但是在某一个时间段只有一个活跃的消费者,这个消费者可以源源不断的去消费,其他人只是他的一个灾备。如果活跃的消费者down掉了以后,其他消费者就可以立马接管,保证整个的处理是相对特别快的。 另外一个方式,更多的是在线业务、订单业务、通知系统里面会用的共享式订阅,就是说对同一个topic,我可能不需要不在乎序,这时候我可以加无限个消费者去扩展消费能力,这些消息以共享的方式分发给不同的消费者。 这是Pulsar在所谓的API模型上做的一个统一,但这只是给大家一个简单的一个概念,最主要的地方是,它其实是把传统的消息系统跟传统的分布式文件系统或者分布式存储系统做了一个整合。 存储与计算分离 另外提出的一个概念其实很简单,就是存储跟计算分离。分离的意思是说我有两层,一层是存储层,可以无限扩容,存很多数据;有一层是所谓的消息层,就是传统意义上的Broker,我可以提供很多低时延的消息投递,还有读尾端的数据。 分层以后带来的一个好处是,每一层都可以独立扩展,比如当我需要更大的存储的时候,我可以只加存储节点。当我需要更多的消费者,需要更多人去读这个数据的时候,只需要加我的更多Broker就行了。分层以后还有一个好处是,我的Broker变成了没有状态,没有状态了以后,做一些容错、扩容就会变得特别简单,不需要搬很多的数据。 在存储层,其实是用了另外一个项目叫Apache BookKeeper。它本质上一个专门针对分布式日志的存储系统。它的定位很简单,就是一个强一致的系统,是一个刷盘落盘的持久化存储,能保证即使落盘,我也能做到低延时跟高吞吐。它的设计会在可用性上做很多的文章,保证一些读写高可用。给大家一个大概的概念,BK可以做什么?BK最开始的一个主要应用场景是HDFS NameNode,它做的是NameNode的HA,就是说NameNode会有一个added log,它其实是整个HDFS的灵魂,就是说你所有对HDFS的Metadata的修改,都会落到added log里面进去。BookKeeper最开始出现就是为了解决HDFS NameNode HA的问题,但后来慢慢就衍生成了一个通用的分布式日志存储系统。 它最主要的两个应用场景,我们概括出来,一个的是数据库,另外一个就是消息或者是流。BookKeeper用在数据库,主要介绍两个,一个是Twitter内部有Key Value存储Manhattan,BookKeeper作为Manhattan的transaction log去实现Manhattan Key Value的强一致性。另外一个是,Salesforce拿Salesforce来做一个类似于Amazon Aurora的一个NewSQL的数据库。所以这就是BookKeeper在数据库的应用场景,我们可以注意到BookKeeper在这里面其实是整个数据库的transaction log,基本上就是append-only的工作负载。 另外一个场景是消息,基本上Twitter跟雅虎都是拿BookKeeper作为整个消息平台的存储。消息基本上也是append-only的工作负载,我之所以一直强调append-only是因为,BookKeeper的整个设计,就是为了日志或者为流诞生的。 分片存储 这给大家做一个简单的介绍,Pulsar的底层用的是一个面向流和面向日志的一个分布式存储系统,Pulsar围绕BookKeeper去构建消息中间件,或者是我们叫流存储的一个概念的话,它在传统意义上的这种topic分区上做了一个概念,就是说我的分区不再是一个物理的分区,其实是一个逻辑上的分区。 逻辑上的分区的意思是,我可以无穷无尽地往分区上追加数据、写数据。但是在底层,我会把逻辑上的分区切成不同的分片,分片会均匀打散,存储到底层的一个存储系统里面。基本上HDFS或者其他的分布式文件系统都是这样的一个思路,所以它本质上就是用分布式存储来做消息系统,或者是做流存储的一个思路。 我们刚才说了分层跟分片的概念,为什么我们说分层分片特别重要,它其实解决了很多可用性、容错、包括运维过程中的一些问题。我举两个例子,一个是关于容错,一个是关于扩容。 容错方面的话,因为它其实是分成两层了,有一层是Broker,另外一层是存储节点。Broker失效了以后,其实它会很简单,因为记得所有的数据其实存在存储节点上,Broker本身是没有任何状态没有存储任何数据的,它只拥有一个分区的所有权。所有权的意思是,我可以提供分区的一个写服务,当它失效的时候,我只需要把所有权从失效的Broker换到其他在线的一些Broker就可以了,你的整个的流量、你的消费者、消费的数据都可以转到新的Broker上继续处理,所以基本上,基本在毫秒级别就可以完成。 BookKeeper的容错上,其实跟传统的分布式文件系统是类似的,因为是计算跟存储分离了以后,你的存储基本上是被Broker层给隐藏了,所有的生产者、消费者都是跟Broker打交道,所以当你一个存储节点挂掉的时候,你的应用端其实是没有任何感知的,而整个失效恢复都是由存储节点在后台进完成。 举个最简单的例子(如下图),在Bookie 2上,就是第二个存储节点上,我的Segment 4挂了或者整个第二个节点挂掉了以后,我Segment 4的副本数据从3变成2,为了保证数据可用性,需要把副本的数量从2调回到3。这时候后台有一个自动恢复机制,从第三个存储节点跟第四个存储节点,把Segment 4的数据重新复制到第一个存储节点上,从而保证数据有副本。所以这个是Bookie的容错,它整个容错会使你的应用端变的相对更能容忍失效的发生。 (编辑:温州站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |