郭斯杰:重新思考流计算时代的分布式存储
|
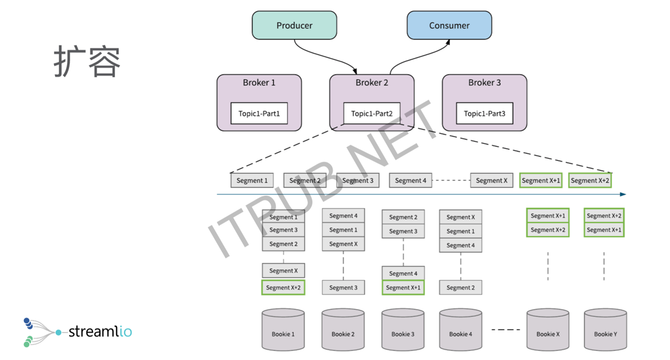
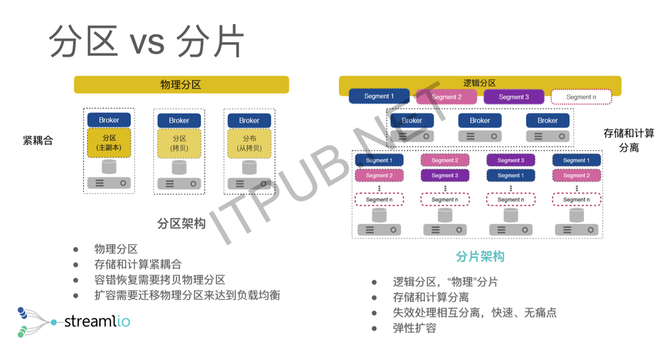
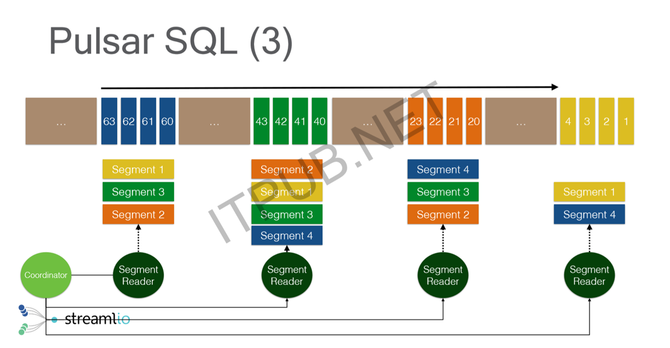
另外一个好处是,扩容会变得特别简单,相当于只需要追加新的存储节点。追加新的存储节点的话,所有的Broker就能发现存储节点被新加进来了,当我需要继续写新的数据的时候,我会开新的Segment,新的Segment就会自然而然地落到新的存储节点,整个扩容就会自动、平滑、均匀地扩散到整个集群里面。这就是分层架构带来的一些容错和运维上的好处。 下面是一个示意图,传统的消息中间件基本上都是基于物理分区去做的,因为它其实不是为了所谓的流存储去做设计的,它的设计理念就是,我只需要保证我的数据存储在一段时间内,我的消息消费完了就可以了。物理分区带来的问题是,数据跟存储节点是强绑定的,对于一个分区,是没办法增长到比存储节点更大容量的,这时候其实不适合用来做流存储或者是长远的一个存储。 另外一个问题是,如果要做容错恢复,或者说做扩容的时候,会涉及到一个问题,因为我的物理分区其实是跟存储节点强绑定,强绑定带来问题是,如果要做负载均衡,要容错,这时候需要把物理分区重新拷贝到新的存储节点上,整个拷贝的过程其实是一个特别消耗带宽的过程。 但是Pulsar的做法不一样,它把物理分区变成了一个逻辑分区。逻辑分区以后,整个分区的容量不再受限于单台机器,而是整个集群,这样的话你能做到真正意义上的流存储。逻辑分区以后,其实是把存储跟计算相互分离,这时候你的失效的处理会变得相对快速,然后没有痛点,然后你在每一层都可以做独立的扩展。 举一个最简单的例子或更形象的一个例子,大家可以看下面这两张图,就是说你分区模型的话,所有分区的数据只能落在某一个存储节点上,你只能在这个节点上无限增长,但是它会有个顶,到了那个顶了以后,没有办法继续保存你的数据了。但是这种逻辑分区和分片的模型,其实是把你的数据切成不同的小的粒度,均匀打散到整个存储空间里面进去。这时候你其实能做到真正意义上的流存储,因为可以无穷无尽地存数据流。 为什么要引入流存储? 存储其实都是有一定限度的,而且很多情况下的话,已经有了HDFS,我在云上已经有太多的对象存储,有太多的文件系统存储,这时候我这些系统已经跑得好好的了,为什么还要引入一个新的系统?这个时候我们其实在想,我们做流存储的真正目的,并不是要再造一个存储系统,而是说我们要在整个数据的抽象上能做到统一,通过流的方式既能表征我的实时数据,也能表征我的历史数据,那这个时候我们完全可以利用已有的云存储,或者更廉价的存储去存已经变老的一些数据。 因为我们其实是一个分片模型,分片模型带来的好处是,能够很自然地知道我的数据什么时候变老,当数据变老的时候,可以很容易地把整个数据卸载到廉价存储里面。但是从应用端来看,整个的数据还是以流的接口、流的表征方式去表达。你在编写计算的时候,不用去区分,你需要访问的是到消息队列里面去算实时计算,还是到HDFS里面去算实时计算,只需要通过统一的一个API就可以做批、流一体的计算,所以这就是我们围绕Pulsar,围绕流的模型以及分片模型做的一个事情。 因为我们觉得在批、流一体的计算时代,你的数据如果还是以不同的方式去表征的话,其实还是存在这种所谓的冗余、数据拷贝、数据重复,然后两个数据源之间不一致的问题,通过流的方式可以统一地表达相应的数据。 三、例子-交互式查询 做流存储有什么好处呢?举一个最简单的例子,就是我们在Pulsar上面做的另外一个事情叫交互式查询。有时候很多应用场景,不仅仅只是想查7天前或者1天前的数据,可能是想把我7天前的数据,再加上这1小时的数据一起查,这个时候业务系统很难办,因为你7天前的数据在HDFS里面,你这1小时的数据在你的Kafka或者是各种MQ里面,你没办法把两个数据串在一起查。 但是通过流存储的方式,我们其实可以很容易做到这一点。因为你整个流表征的是,历史数据跟实时数据,其实在统一的一个数据抽象里面,你的数据只要进到流里面,就是可以查的。这种交互式查询,具有传统意义上,像Hive这种交互式SQL能带来的一个复杂性,就是我可以写很复杂的SQL的查询,然后我同时还具有streaming SQL的实时性,但它不能完全等同streaming circle,更多的是说我编写了一条SQL,我让它不断的在那跑,然后它吐结果。交互式查询更多的是说,我一旦有一个需求,需要查我的历史数据加实时数据的时候,这个时候叫交互式的查询。 我们在Pulsar里面做的一个事情叫,我们没有再去造一个SQL的轮子,而是用Facebook的Presto做了一个深度的开发。为什么我们用Presto,因为它本质上是一个纯的SQL查询引擎,它不带自己的存储节点,但它有自己的一个runtime,所以你可以运行相应的一个SQL查询。而且它可以查询不同的数据源,就是说如果你的业务是在已经在HDFS,你不想动了,但是你新的业务跑在Pulsar上,然后你想把这两部分的数据进行一个join或者是关联查询,这时候Pulsar可以支持不同的数据源进行查询,这时候不需要你把所有的数据都导到Pulsar里面再进行一个查询。 它的实现其实相对特别简单,就像我刚才说的,整个的数据它是一个流,流被切成了不同的分段,不同的分段其实存储在不同的存储节点上,即使最尾端的分段,其实只要数据写进来了,就可以读。所以当你做SQL查询的时候,你的访问不再是受限于分区的数量,就是说,不再是当只有五个分区时,并发度只能是五。因为整个的分区是个逻辑分区,你的分片可能是一百个分片,这时候如果一百个存储节点,甚至是一百个执行节点,并发度就可以是一百,整个SQL查询的执行效率就会特别高,因为它是以分片为粒度,而不再是以分区为粒度。 (编辑:温州站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |