丁俊:京东商城K-V存储产品的演化之路
|
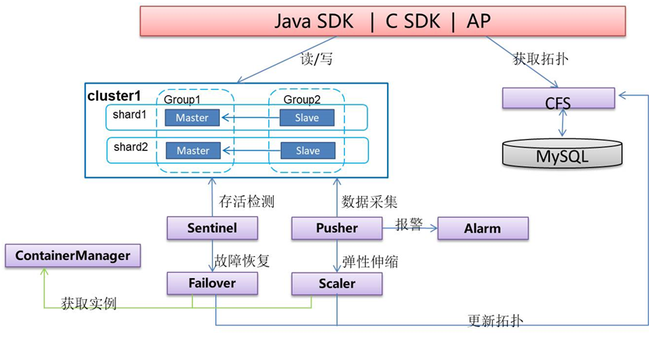
【技术】本文根据丁俊老师于第十届中国系统架构师大会(SACC 2018)的现场演讲《JD K-V存储产品演化之路》内容整理而成。 讲师介绍: 丁俊,京东商城在线存储部负责人,主要负责分布式存储系统、分布式消息系统、分布式服务框架等产品的开发和维护。 正文: 大家好,我今天讲的题目是京东KV存储产品的演进之路。我不会具体讲每一个产品是怎么做的,而是重点去讲我们在开发中碰到的一些问题,以及我们是怎么解决的。当然这些问题的解决方法不一定最优,也不一定完全适合大家。大家可以共同探讨,作为一种解决思路。 我今天主要讲三个部分,一个部分是内存存储(jimdb),另一块是持久化存储(sharkstore),还有一块就是我们目前想要做的混合存储。 内存针对的是一个高吞吐、低延迟的场景;持续化存储更强调的是可靠性和容量上面。我们后面想做一些混合存储,主要是因为在业务发展过程中有很多数据慢慢从内存里面沉淀下来,可能不常使用,而因为业务、成本等各方面的考虑,没有将其从内存中挪出来,我们就想能不能通过平台统一把这些事情处理一下。 下面我大概介绍一下我们各个产品的时间节点。2014年我们内存存储产品的第一个版本上线,当时是公司内部有各种各样的一些开源产品的使用,每个小组也有自己的维护系统,包括开发一些管理界面,维护工具等等,公司决定把它统一起来,由一个独立的团队去提供这样一个产品。 2014年上线以后,业务量增长比较大,在2015年的时候,我们就面临了一些新的挑战。随着业务数据的增长,比如在内存里面,有一些业务数据可能今年的增长量是前面所有年份的总和,甚至还要多。2015年数据的扩容,包括我们服务的产品越来越多,搭建的集群越来越多,它的故障恢复能力都给我们带来了一些挑战。第二个版本重点解决这些问题。 2017年,我们有了异地的机房,就需要支持中间件的异地多活。现在的这个产品,我们也做了异地多活的解决方案。2018年内存方面的大部分事情,主要的矛盾解决差不多了,我们就做了持久化的存储,去解决一些成本上的问题,包括和一些厂商去探索新的存储,比如这个介质是不是可以节省一些内存,从降低成本上去进行一个考量。2018年当我们的存储系统上线以后,就在这个基础上,为一些业务提供了分布式锁,包括配置分发的功能。再后面就是我们正在研发中的一个事情,希望能够把混合存储提上去。 内存存储的实践与挑战 现在讲第一部分,内存存储。这里先讲运营数据,当然不是为了说明这个系统有多复杂,其实系统不是特别复杂,主要是我觉得一个系统碰到的主要问题和解决问题的思路,可能是随着系统的数据量访问压力来的,所以说大家在挑选方案的时候,还是要结合自己的业务特点,从成本、实现的难度,维护人员的数量、紧急度等等一些方面去考量。平常我们整个平台大概每秒钟可能有上亿次的访问,内存的进程数大概在10万级以上。 下图是我们内存存储的架构图。 该架构的主要特点包括:高吞吐、低延迟,能够自动故障恢复,可以在线伸缩,能够进行广域复制等等。 下面我主要讲一下故障检测。说到故障检测,大家在部署的系统当中其实都会面临这个问题,都需要容灾,对硬件、网络的故障等进行检测,让你的业务避免受到这些故障的影响,提升可用率。我们在做故障检测的时候,如果说我本来就没几个实例,可能就是部署一个哨兵,或者有一些别的方案去探测。检测一个服务是否存活,可能常用这几种方法:一种是主动探测,另一块就是由本身提供服务的人,去上报它的状态是不是好的。 如果故障检测没有做好,会有什么问题?其实如果说你是一个没有状态的服务,探测错了也不会引起太多的问题,最多可能就是导致性能的偶尔波动。作为一个有状态的服务,如果检测错了,很可能导致的后果就是,可能你的数据会写丢。比如说你检测到一个master,它是一个写入点,你认为它是故障的,有一部分节点还在往这个节点上写入,另一部分节点认为它故障以后,可能会选出一个新的写入点。如果你的业务同时往两个写入点进行写入,势必就会导致数据丢失。 导致这种检测误判的主要原因有哪些呢?目前我们主要面临的一些问题,一个就是网络的分割――当然如果部署的节点比较少,本身可能就这一个网络、一个机架里面或者一台交换机下面,这种故障的可能性会小一些。但是当你的服务部署在整个机房的各个角落,包括甚至可能在同城的多个机房里面,这种网络的故障出现的概率就会大很多。另外其实我们还碰到一个问题,就是一个长任务的执行导致系统阻塞,探测的时候,可能会探测到它不是存活的,因为它没有在一定的时间内给你一个响应。比如说你认为多少秒以后它就“死亡”了,如果说任务执行的时间超过这个时间,你也可能会认为它是死亡的。 大家可以认为一个长期阻塞的任务是“死的”,当然也可以认为它是“活的”――因为本身进程还在,这个要看你的业务特点。但是我们认为,这种场景尽量不要把它“判死”,为什么?我们发现往往你把它“判死”、“杀掉”、在别的地方恢复起来以后,业务往往还会执行相同的事情。相当于不停地“杀掉”-起来、“杀掉”-起来,进入这样一个恶性循环中。 对于这些问题,我们主要有这几种解决办法。第一个,我们把探测点部署在机房的各个角落里,分布在不同的机架和交换机下面,他们组成一组探测服务,共同去投票决定这个服务是“死亡”的、还是存活状态。这是一点,解决网络的问题。第二就是,对于任务阻塞的情况,我们是在服务器上面部署一个agent,因为本身服务器上有agent去做一些指标采集等,也会做一个判断进程是否存在的服务,结合这两点去防止误判。 下面说一下故障的自动恢复。恢复其实很简单,就是你探测到它不存活以后,可能通过一系列的手段,比如说slave“死了”,副本“死掉”以后,再加一个副本就可以了。如果说你的写入节点master“死掉”了,从现有的副本里面、slave上面去提升一个,提升为master就可以了。我觉得在做业务系统的时候,为了提升使用率不一定要完全去依赖这种探测的服务,你还应该有一些别的手段,在客户端可以做一些容错的策略,比如说如果你是读写分离的,那能不能够在slave“死掉”以后自动去读一下master,恢复以后再去读slave。比如说,如果我在同城有别的机房,有两个对等的集群,那我能不能在这一个集群访问不了的时候,业务客户端去访问另一个集群。在这种规模比较小的时候,可能大家实际开发成本都是相对比较低的。 (编辑:温州站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |