丁俊:京东商城K-V存储产品的演化之路
|
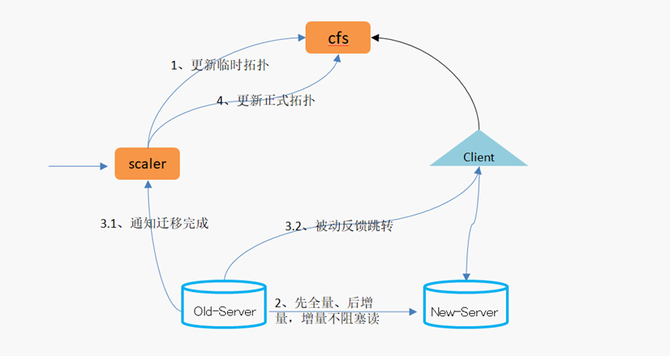
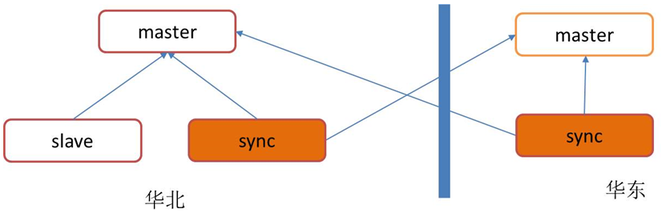
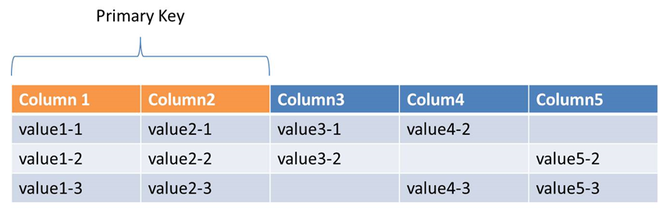
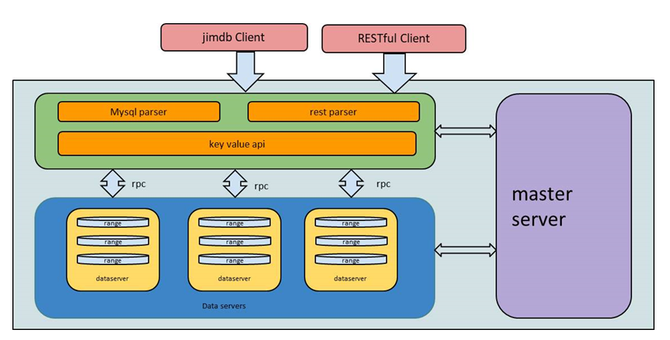
还有一个问题就是,是不是所有的故障都一定要去恢复。这个场景其实不太经常碰到,但是如果碰到了,确实需要注意一下。因为我这么多年做这种服务,偶尔也有碰到过那么一两次。就是说我发现一个大面积的故障,比如探测到某一个机房断电了,那要不要去做故障恢复?也许这种场景下去做故障恢复带来的后果可能更大,可能你还没有完全把数据都自动恢复好的时候,机房可能已经帮你把电也已经通上了。而在自动恢复时,会占用大量内部网络的流量,对现有业务产生影响。所以在这里我主要想提一句,有一些场景可能需要你去做一个系统的决策,做一个智能的判断,但有时也不一定要做的这么复杂,如果系统简单,那做一个开关就好了。 下面说一下迁移的过程。当系统的数据量越来越大时,原来分配的空间可能不够了,需要扩容,系统需要升级,这时你也需要做数据迁移,因为数据在内存里面,没有办法进行原地升级。我们知道在数据迁移中,通常第一步可能就做一个快照,做完快照以后再补增量。在这里要提一句,就是说我们在补增量当中,实现完第一版以后,发现系统有时会卡顿一段时间。因为首先每个业务写入的流量大小不一样,有的业务可能刚好碰到写入量比较大的那段时间,你会发现增量的数据比较多,这个时候就可能阻塞住。 在线迁移流程图 为了保证前后、新旧服务的数据一致性,你可能需要把老的写入给停了。后面发现一个业务特点就是,读比较多一些。我们可以把读给放开,让它在迁移的过程当中,只阻止写――也就是变化的地方。 下面说一下内存存储的广域复制的问题。我可能在华东、华北有两个机房,我的服务部署在华北,有一个master,也有一个slave。现在我可能需要在华东也提供一个服务,常用的就是把一个数据复制过去就可以了。这里有一个前提,因为它是在内存里面,所有的数据都在内存里面,我能不能够直接在华东挂一个副本到我的master去。 个人认为在业务量比较小、数据比较少的时候,这种方案是可以的。但是大家都知道,广域网络上面可能网络延迟比较高,网络的质量比较差一些。这就带来一个问题,可能会有中断。那我要缓存的、要同步的数据,可能在内存里面会积攒比较长的一段。这样,当我数据量比较少的时候,能不能把缓冲区直接调大,就可以缓存更多的增量数据,避免这种存量。不过平台、服务的集群很多的时候,如果把每一个实例内存都调大,可能浪费的资源就比较大了。 我们采用的方案如下图,在华北新建一个同步的模块去模拟slave,把master的数据同步下来,保存在本地的机房,再把数据发送给华东的集群。这里我们会有两个master,意味着就可以接受两个地方写入,目前我们线上也有这样的一些服务在跑。比如,大部分是华北作为一个主要的集群进行写入,华东是不接受写的,只有读,但也有一些业务可能需要在两地同时多写,我们也提供在华东接受写入。 这里可能会面临一个问题,就是华北写入的key复制到了华东,如果华东也要往回复制的话,同一个key是不是就在这里“转圈”?其实我们在key里面打了一个标,它从哪个地方写入就打哪里的标,当sync服务在复制这些数据的时候,会跳过这些key,这样就实现了两个集群之间的相互复制。当然这里也有一个问题是没有解决的,需要业务去解决,比如说华东和华北同时写同一个key,这可能就面临一些问题。第一,复制是延迟的,第二就是一致性等问题。我们这里其实没有去解决,还是靠上层的业务去规避。就是说在华东写入的key不会在华北写入,华北写入的key不会在华东写入。或者业务上能够接受这种混写,就是说以谁为准都可以。 持久化存储的实践与挑战 下面讲一下持久化存储。其实持久化的KV存储其实有很多开源的实现,大家的一些实现思路也都大同小异。我们也一样,选用了一些常用的开源组件,在这基础之上进行开发。自己开发这个系统的原因,一方面是为了更好地和内存存储的API等等兼容,还有一些自己的业务特性在里面。 持久化存储的特点包括:1、分布式强一致;2、支持在线分裂、自动故障恢复;3、支持schema,海量数据;4、支持范围查询,单表操作。 下图是持久化存储的逻辑视图,其实KV的存储里面,大家的key和value不一定是列的,那我们选用这样一种方案,一方面为了方便,比如说后面我们要兼容MySQL的协议,还有就是从我们自己的业务特点来看,目前这种跟MySQL一样的这种结构可能对我们来说已经能够满足需求。相对来讲,我觉得这种方案可能还有一定的灵活性,也有一定的约束,比较折中一点。然后key是可以由多列去组成的。 下图是持久化存储的结构图,其实这种持久化存储,包括对象存储等等,大家的结构可能都差不多,有一个接入层,有一个master去管理元数据,有保存数据的地方。 这里可能需要介绍一下,我们的data servers是基于rocksdb去实现的。其实大家上网去查这种持久化存储,可能首屈一指的就是rocksdb,它各方面性能,写、读都非常优秀,所以我们也选择了这么一种方案。但后面我们在一个场景上测试的时候就碰到了一个问题,主要是rocksdb compact带来的影响。这里我简单介绍一下compact产生的原因,对于rocksdb来讲,它就是一个基于日志结构的合并树。假设我的左手边是一棵无序写入的、按写入顺序进行保存的树,而我的右手边是一颗有序的树,然后不停地把无序写入的数据往右手这边的有序树上去合并。一个是为了保证读的性能,另外一块就是说它有一个特点,比如我的删除,其实在无序的树里面去写入一个Key,做一个标记它是删除的,并没有真正在我的右手边有序的树里面去删除,只是打了个标,然后通过后台的GC把这些数据给清理掉。基于这两点,它需要不停地把无序的树和有序的树进行一个文件的合并,合并的动作就是从无序的树里面挑一个文件,看Key的分布,在有序的树里面也挑选相同或者一定跨度范围内的Key的一个文件进行合并。 (编辑:温州站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |