丁俊:京东商城K-V存储产品的演化之路
|
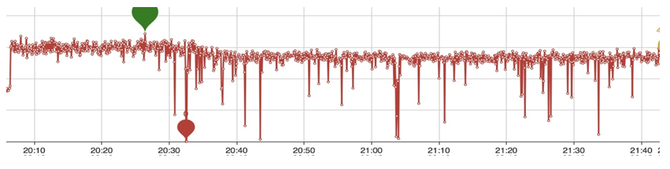
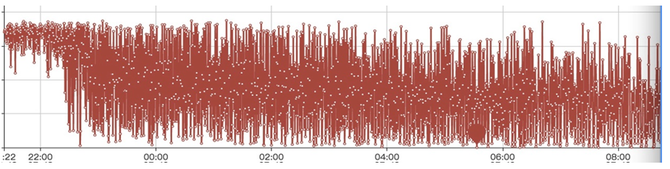
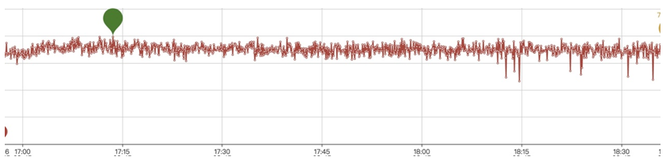
另一块就是说因为每一层数据不能够保证Key写得太大,它会一层一层往下写,下面的虽然说每一层不是有序的,为了查找的效率,包括GC掉一些删除的Key等等,它会往下进行合并,每一层也会合并。这里面其实大家就看到一个问题,比如说我有一个Key,从写入以后就再也没有改变过,也没有删除,在这个过程当中,可能我就会被来回搬运很多次,被写入很多次,这就导致了一个写的放大。大概就是这么一个流程。 我们会发现在一段时间内,当我一个rocksdb的进程、数据量在100多近200G左右的时候,它其实性能还维持的比较好(这里提一下,我们使用的是基于NVMe的SSD)。当它超过一定的量以后,你会发现写入的性能就有一些“尖刺”了,有的可能就直接掉到0。作为一个在线服务来讲,这种问题是我们无法接受的。举个例子,大家作为消费者,可能都不希望在大促销、“秒杀”的那一刻,服务如果出现延迟,那么可能促销的时间点已经过去了。当然如果是一个离线服务,我觉得是可以接受这种短暂波动的。 下面是系统长时间跑的一个图,大家可以看到,越到后面波动就越大。 针对这个问题,我们目前采用了一个Key-value分离的方案。我们是基于rocksdb里面blobdb功能的完善和改造。这里简单介绍一下Key-value分离是怎么实现的,就是说我有一个Key写进来以后,还是和原来一样保存到rocksdb这一套结构里面,同时我把我的value写在一个顺序追加的文件当中,然后把这个顺序追加的文件的位置,比如文件编号、基于这个文件的偏移量等等,把它写在一个索引里面,把索引信息和Key保存在一起,索引信息作为一个原来Key对应的value保存起来,相当于中间加了一层。这样做的一个好处就是说我在做一个有序整理的时候,就是排序合并的时候,不用先去搬弄我的value。 其实这里面也隐藏了一个问题,就是说它并没有解决所有的场景,可能只对Key-value比例比较大的场景比较合适。比如说key可能就几十个字节,而value可能上千或更大,这种场景其实是非常合适的。如果value本身就比较小,可能几十个字节,和key差不多,还多出个索引来,其实这种场景也是解决不了的。 然后,如果说你的比例能达到一比几十的话,你一块盘几个T的容量,内存里面保留几百G的key的数据,也许就能够很好的去解决这个问题。包括你这对一台物理机进行多个实例的部署,也可以缓解这些问题。当然业界也有一些别的探讨,比如说结合SSD磁盘的一些特性,SSD磁盘本身也会在后台做一个GC,也许就可以和rocksdb的GC合并起来。 下面就是我们改动以后业务测试的一个性能表现,相对来讲就比原来平滑很多。 讲完存储那一块碰到的问题以后,下面就说一下raft成员变更。因为我们的数据,包括云数据、业务数据和元数据都是基于raft复制的,它可以在线扩容,也可以进行一些故障恢复,势必就会涉及raft成员的变更。当你在做数据迁移负载均衡的时候,成员就需要变更。比如说一个磁盘快满了,我需要把一个副本从A机器搬到B机器去,我们的做法就是在B机器上面加一个节点,加上以后再把A机器上的副本删掉。 这里面就碰到一个问题,如果这个时候刚好A机器有故障,你就会发现raft就没办法正常工作了,因为它现在的成员是四个,新加入的成员和有故障A镜像的副本同时不能工作,这个时候其实你是有两个节点是坏的,两个节点是好的,它没有办法保证大多数的成功。 大家可能就问,那我能不能先把A机器上的节点删了,让我的成员从三个变成两个,然后再把一个别的节点加进来,是不是就能解决这个问题?其实在一定程度上是能缓解这个问题,但这里面可能也会碰到新的问题,就是说当你刚好把A镜像的副本给删掉以后,三个节点删了一个还有两个,如果再有个节点出现故障的话,你整个数据可能都没有办法自己去恢复了,你就需要强行去干预它,这可能就涉及数据的一个安全。 那么我们现有的方案是怎么解决这个问题的?其实我们大概思路就是,首先让新增的raft成员只复制数据,不参与到投票里面,同时也不会发起Leader选举,让它作为一个“学习节点”。当这一个新增的节点复制完数据以后,我的Leader会知道它复制到哪了,就认为它已经跟上进度了,再把它提交到成员里面去,同时把另一个节点删掉,这样就能够保证这个工作比较顺利地进行。如果这个时候即使有一个新的节点有故障的话,也能保证有两个节点在。 这里提到其实它有个特点,就是新增一个成员的时候,是会重新发起Leader选举的。还有一个就是,如果我这个节点(follower)数据落后了很多,断开网络以后重新加进来,也会发起一次Leader的选举。那Leader的这种选举、切换,其实是需要时间的,对性能会有干扰。 当然raft的作者也有提到怎么解决这些问题。就是新增的节点加进raft组以后,先询问一下,跟现实中的选举一样,你在正式选举之前,可能需要去各个社区拜个票,后面真的选举了,让人家选你。它也一样,就是说加进来以后,先不发起Leader选举,而是先去拜个票,跟每一个成员沟通一下,能不能给我一个机会当Leader。如果大多数的人反馈你可以,那就进行选举。如果说现有的Leader挺好的,我不能让你当,或者是说你的数据落后于我,你不会成为Leader,那就没必要再发起leader选举了。作者提出了Pre-Candidate算法,在发起之前就先进行一次预选举。如果预选举时能得到大多数的投票,再增加term,进行正常的选举。这样就是大大的降低了因为一些网络,包括数据的迁移平衡等因素导致的性能波动。 (编辑:温州站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |