内部专家亲自揭秘!滴滴对象存储系统的演进之路
|
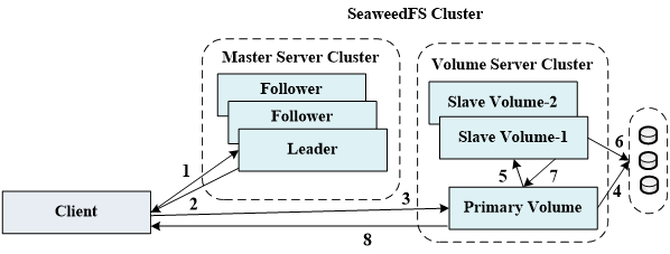
【技术】本文根据汪黎老师于第十届中国系统架构师大会(SACC 2018)的现场演讲《滴滴对象存储系统的架构演进实践》内容整理而成。 讲师介绍: 汪黎,博士,中国计算机学会存储专委委员,曾获中国计算机学会优秀博士论文、首届中国开源软件竞赛银奖等奖励。主要研发领域为文件系统、操作系统、分布式存储,为知名开源项目LVS、Ceph成员。曾任国防科技大学计算机学院副研究员,教研室主任,天河云存储研发负责人;现担任滴滴出行高级技术专家,滴滴云存储研发负责人。 正文: 大家好,我分享的题目是《滴滴对象存储系统的架构演进实践》。 首先,什么是对象存储系统?当前对象存储系统这个概念稍微有一点混淆。一般有两种定义方式:一种是通过存储系统本身的技术实现路线来将其定义为对象存储系统。比如经典的、在高性能计算常用的Lustre文件系统,它的后端就是一个典型的对象存储设计思想。现在非常流行的Ceph,它的后端RADOS也是对象存储的架构。另外一个定义方式,是从存储系统的应用场景来定义的――即某个存储系统适用于对象存储这个场景。而今天我想交流的,就是基于第二种定义方式的对象存储系统。 那么,对象存储的应用场景有什么特点?它一般存储的都是静态的、非结构化的数据,比较典型的有图片、音视频、网站的静态资源,还包括一些比如虚拟机的镜像,快照,以及备份数据等等。这样的数据,普遍具有一次写、不修改、多次读、较少删除的访问特点。另外,数据对外访问接口一般是通过HTTP的接口来访问,对延时的要求并不太高。但对象存储系统对海量数据存储要求是很高的,另外对数据可靠性的要求也很高。 滴滴对象存储系统GIFT V1.0 滴滴的对象存储系统,内部称为GIFT,是为了解决公司小文件存储问题而开发的对象存储系统,比如图片、网页静态资源等。 访问的方式为http://<domain>/<ns>/<key>,其中ns即namespace是全局唯一的,ns和key均为用户指定,常见的接口就是上传、删除、下载。一开始这个系统的架构比较简单,主要分两部分,第一部分是API层,用Go实现的接入服务,为用户提供文件上传、下载、查询等功能。后端的存储服务,用于存储文件数据以及元数据。文件数据使用SeaweedFS存储,它是开源的,参考了Facebook的Haystack,不过Haystack本身没有开源。另外在我们一开始设计时,数据和元数据是分离存储的。因为不管是SeaweedFS还是Haystack,要支持大量元数据的存储和复杂的查询,其实是相对困难的。所以元数据单独使用Mysql集群进行存储。 这里简单介绍一下Facebook Haystack,这是一个比较经典的对象存储系统。Haystack是Facebook用于存储图片等小文件的对象存储系统,其核心思想是采用多对一的映射方式,把多个小文件采用追加写的方式聚合到一个POSIX文件系统上的大文件中,从而大大减少存储系统的元数据,提高文件的访问效率。当要存大量的小文件时,如果用传统的文件系统,一对一地去存小文件,存储空间利用率很低、查询的开销非常高。 另外介绍一下SeaweedFS的架构。它包含两个组件,一个是数据存储集群,即Volume Server Cluster,每个volume server对应一个磁盘,每个磁盘有一系列的volume文件,每个volume文件默认大小为30GB,用于存储小对象。每个volume文件对应一个index文件,用于记录volume中存储的小对象的偏移和长度,在volume server 启动时缓存在内存中。 这也是Haystack的一个重要设计思想,它做了一个两级的元数据映射,第一级把它映射到一个大文件,这样文件系统本身的元数据开销是很小的。第二次映射的时候,只需要在大文件内部去找它的偏移和长度。而且做完两级映射之后,可以使大文件里对应的小文件的元数据全部缓存在内存里面,这样就可以大大提高它的查找的效率。 另外一个组件称为Master Server Cluster,运行的是raft协议,维护集群的一致性状态,一般与volume server混部。volume server会向它上报自己的状态,然后它能够维护整个volume server cluster的拓扑。同时它还负责对象写入时volume server的分配,以及负责数据读取时volume id到volume server地址映射。 下面我们展开来讲SeaweedFS。首先上传过程,第一步是客户端先与master server cluster的leader通信,leader进行volume分配,给客户端返回一个fskey及volume server地址,fskey包含volume id,needle id及cookie三部分。Volume id跟volume server对应,needle id用于在一个volume内做索引,cookie用于安全考虑,大家有兴趣进一步了解的话,可以参看Haystack的论文。 第二步,客户端将文件及fskey发送给对应的volume server,该volume server为存储主副本的server,称为primary,primary将文件追加到对应的volume文件尾部,并将offset,length,needle id记录到对应的index文件。 Primary将文件写入后,将文件发送给两个存储副本的volume server,称为slave,待slave返回写入成功后,给客户端返回写入成功。 (如下图) 删除操作体现了Haystack的思想――它的删除是异步删除的。客户端用对象对应的fskey与master server中的leader通信,得到fskey中volume id对应的volume server地址。这实际上是做了一层间接,因为volume server有可能会挂掉,所以不能直接把volume server的地址给client。同时也便于master做一些负载均衡。每次读的时候也会首先跟leader通信,然后拿到volume server地址之后,再去访问主副本。然后主副本就会把这个对象做一个标记删除,它不会真正去删那个文件,不会真正从大文件里把那部分挖空。只是标记一下,不会做数据删除,Volume server会通过一个异步的compaction操作来回收数据。 异步compaction是什么?就是说这个大文件,每删一个文件就会留下一个空洞,如果Volume里面已经有很多的空洞了,现在决定要重新用这个资源,就会做一次compaction,就是把Volume里面剩余的、还没有删除的文件全部拷出来,重新把它拼成一个连续的文件,然后把其他的空洞对应的地方释放掉。 (编辑:温州站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |