内部专家亲自揭秘!滴滴对象存储系统的演进之路
|
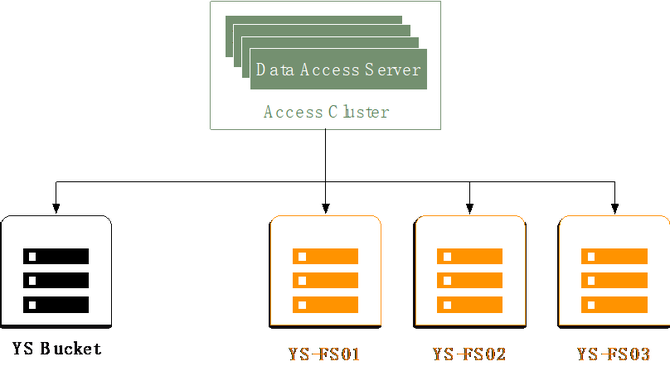
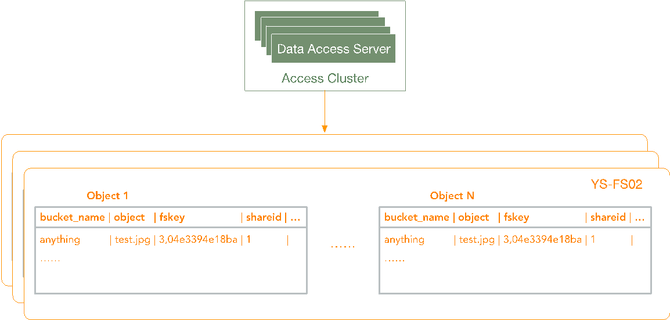
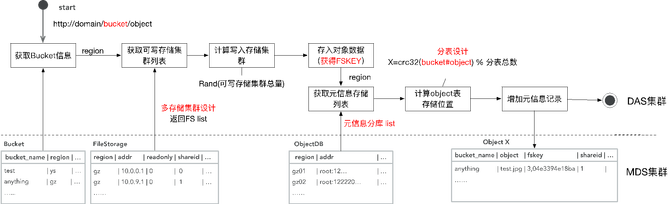
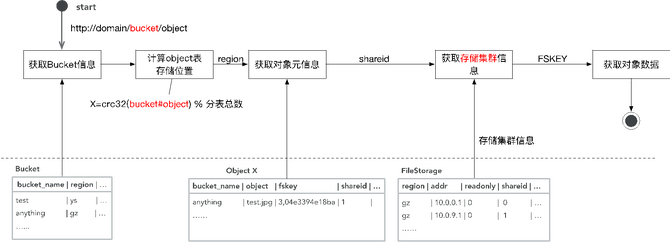
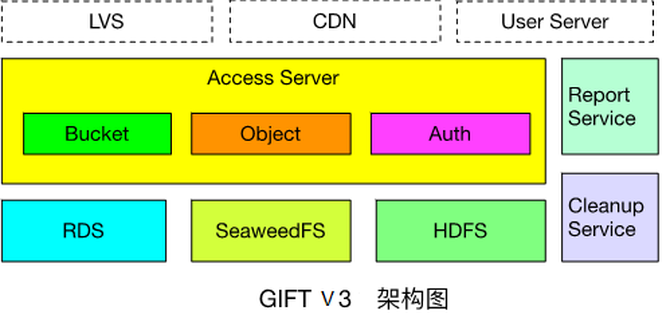
下载其实跟删除类似,首先客户端用对象对应的fskey与master server中的leader通信,得到fskey中volume id对应的volume server地址,然后访问volume server,volume server根据volume id,needle id访问对应volume文件的index文件,得到对象在volume文件内的偏移和长度。Volume server再访问对应volume文件,给client返回对象数据。 伴随业务增长下的第一次演进――GIFT V2.0 以上介绍就是GIFT最早的版本(V1)。随着本身数据文件量和业务量的增加,问题也越来越多。其中的一个表现是什么?随着业务量不断增加(TB -> PB),架构无法支持PB级存储。因为数据存储SeaweedFS是有中心设计模式,集群规模增大存在并发访问性能瓶颈问题。读写请求必须先经过master server,再访问volume server获取数据。master server运行raft协议,只有一个leader在工作,其它为follower。只有leader处理读写请求,存在单点性能瓶颈。在高并发的情况下,访问延迟明显的增加。然后就是,我们最早的设计,元数据的存储为单库设计,所以是所有用户集群共享的,造成QPS受限。 所以我们就对它做了一个架构的演进。主要的思想,首先在数据存储方面,我们从业务逻辑角度支持接入服务管理多个SeaweedFS集群,就是多个存储子集群。当一个SeaweedFS集群的容量达到阈值时,将其标记成只读,新数据写入其它集群。而且我们支持SeaweedFS集群的动态加入、动态注册。集群扩容过程为,首先一个新的SeaweedFS集群会向接入服务注册,然后接入服务将其加入可写集群列表,接入服务对上传文件的bucket, object信息做hash,选取一个可写集群,进行写入操作。这是从数据的角度解决QPS和存储容量的需求。 从元数据的角度,我们支持了支持多库分表模式,可对不同用户集群采用不同库,解决海量文件并发访问问题。下面具体介绍一下。从元数据的角度,我们做了一个分库和分表。首先我们可能有不同的Region,而不同的Region下面可能还有不同的用户集群(下图1)。我们除了有一个全局唯一的配置库以外,从对象的元数据库的角度,做了一个分库和分表的设计。(下图2) (图1) (图2) 具体到上传过程,用户指定了它在一个Bucket的下面一个object。首先会根据Bucket的信息,去查全局唯一的一张表,从这里查到Bucket对应的Region在什么地方,然后得到Region之后,才会同时去查Region作为关键字所对应的存储集群有哪些。这也是一张全局唯一的表,Region下面因为会有一系列的支持存储集群,就是SeaweedFS集群。进一步就会去做一个调度,然后决定去写入哪一个存储集群。 写完之后,SeaweedFS会返回一个fskey,我们需要存下来,fskey以及对象本身的一系列元数据存在什么地方。从元数据存储的角度来讲,每一个Region下面针对不同的用户集群有一个分库。查这张全局的表,我们可以得到Region下面真正存这些元数据的库是哪个,然后再去访问那个库。在那个库下面我们又进一步做了一个分表的设计,就是说这个库下面的所有这些对象的元数据,是有一系列的分表的,而分表的依据就是把Bucket和object联合起来,再做一次CRC,再模上整个分表的总数,就得到了它要存到哪个分表里面,然后就把它对应的这一系列的元数据存进去。这样就从元数据的角度去解决了整个集群的海量PB级可扩展的一个设计。(如下图) 下载就是反过来,先拿到Bucket查这个表,得到它所在的Region,然后就得到它对应的元数据的数据库,用刚才说的CRC得到数据库下面都有是哪张分表。然后就可以从分表里得到它对应的元数据,元数据里面是记载了它所存储的数据存储集群的信息。拿到数据存储集群的信息以及fskey后再去访问对应的SeaweedFS集群,就可以得到对象的数据。整个就是这样的一个过程。(如下图) 以上就是GIFT2.0版本的设计,它的可扩展性已经很不错了,已经能够支撑到一个PB级的存储。 昙花一现的GIFT V3.0与更好的V3.5 随着我们业务发展,有了新的需求,一个是之前我们这套系统主要提供对内服务,而我们现在还想支撑一个对外服务,这时我们可能就需要加入一些像计费、认证的逻辑,同时还需要去支持大文件的存储,就像我们刚才提到SeaweedFS其实更多是存小文件,所以我们又做了一个3.0版的一个设计。 主要增加了一些功能组件:接入服务提供认证和数据操作接口;存储服务,小文件存储在SeaweedFS,大文件存储在HDFS;Report Service(上报服务)用来定时推送用户统计量信息;Cleanup Service(清除服务)用来删除过期数据;RDS主要用来存储object和fskey对应关系以及配置表信息。架构图如下: 其实3.0这个版本存在的时间不是那么长,因为还觉得它存在一些问题:对于SeaweedFS,运维复杂,不支持故障自恢复、需手动恢复数据,且恢复以volume为粒度;不支持数据rebalance;Master server维护volume id与volume server的映射关系,为单节点,所有请求经过master server;不支持纠删码。 HDFS存在NN问题,它本身其实也是一个有中心化设计。而在GIFT应用场景下,元数据已由RDS存储处理,我们希望存储服务本身尽量保证可扩展性、高可靠性,不希望在这里还有一些元数据限制它的可扩展性,所以存储服务应尽量采用无中心化的模式。然后HDFS本身也不太适合小文件。虽然它本身的出错恢复有一些考虑,但我们觉得还是不够强,随着集群规模越大,出错恢复越慢。另外还有一个问题,整个架构中大小文件用两个系统去存,本身对我们的运维成本控制不太理想,所以我们进一步想把存储的后端再做一些迭代和优化。 (编辑:温州站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |