内部专家亲自揭秘!滴滴对象存储系统的演进之路
|
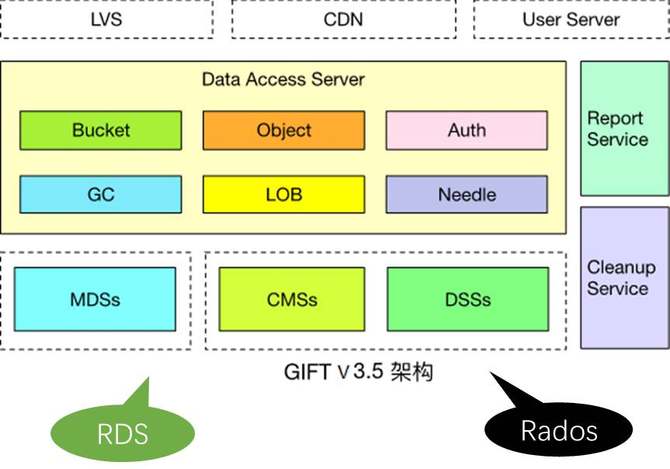
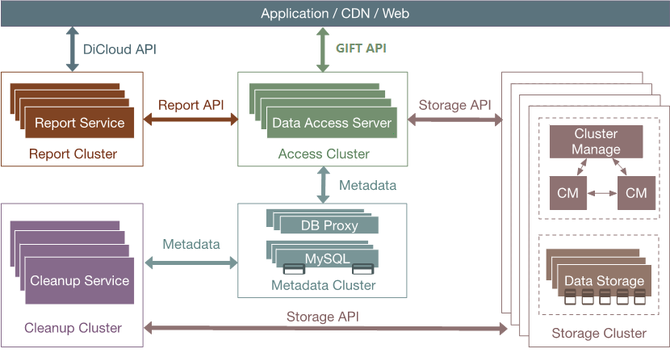
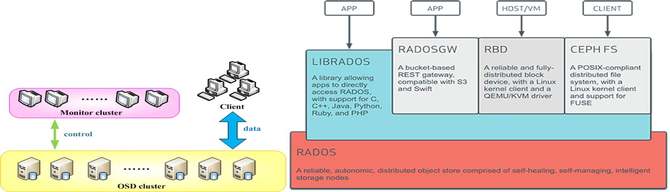
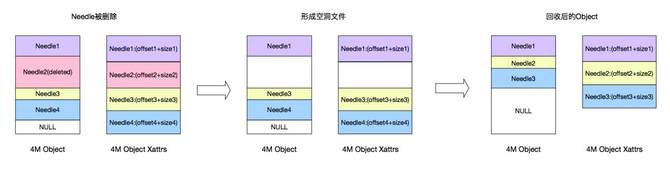
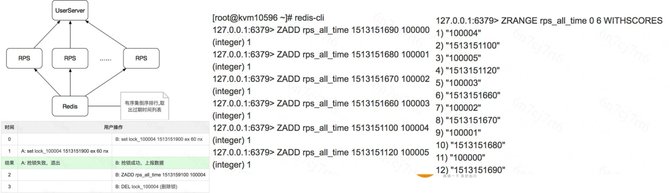
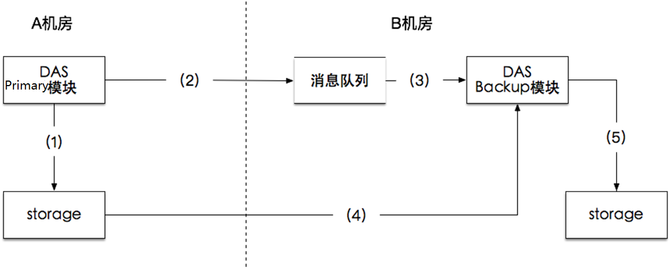
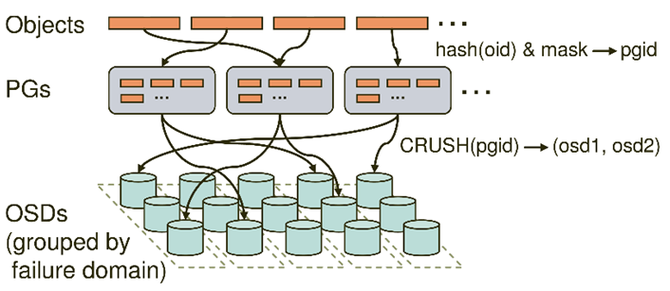
之后,就是GIFT3.5版本。我们把存储底层换掉,采用CephRADOS object storage。Ceph大家比较熟悉,现在应该是开源的云计算场景下应用最多的存储组件。我们决定存储底层换成RADOS统一去支撑大小文件。用这样一个架构去支持大小文件,当然有一些逻辑需要我们自己做,比如说小文件的合并,就像刚才介绍的思路,跟Haystack、SeaweedFS都完全类似。 就是把一系列小文件聚合到一个RADOS的大对象里面,聚合的方式用追加写。大文件做分片。删除异步做GC。 下面介绍整个架构。当前的架构就是最前端有做负载均衡的LVS,当然也有CDN,因为提供对象存储,尤其对外服务,CDN是必不可少的组件。然后数据接入服务,这里面支持Bucket、Object的逻辑,还支持认证的逻辑,然后支持大文件LOB小文件Needle这样一些RADOS这一层的业务逻辑,要做聚合、做分片。然后新的组件有两个,一个是CMS,维护整个Ceph集群本身的拓扑一致性。DSS就是RADOS的一个存储组件,类似于刚才的volume server,主要是负责数据存储。MDS是提供元数据服务的。上报服务和清除服务还是延续3.0的设计。 下面讲我们为什么要用RADOS。RADOS是国际上广泛部署使用的大规模分布式存储系统Ceph的底层存储组件,提供可伸缩、高可靠的对象存储。它的优势在于:高数据可靠性,数据冗余支持多副本或纠删码,支持scrub发现静默数据错误;无元数据服务、去中心化的设计,良好的横向扩展能力,支持PB级存储;运维简单,数据自恢复,集群自伸缩,数据自平衡;所有组件集群化设计,无单点故障。RADOS在生产环境的应用广泛。 下图是Ceph的架构,Client提供标准块、文件接口的访问能力,Monitor监视和维护集群状态和拓扑结构,OSD存储数据。 接下来具体介绍,在这样一个架构下一些具体问题的处理方式。第一个是怎么支撑大文件。对于一个大文件来讲,我们可以在业务这一层做分片。对于大于4M(可配置)以上大文件,存储到多个rados对象,提高大文件访问性能。因为一个大文件是分别存到了多个盘上面,在读取的时候就可以并发了。然后是小文件的设计思想,小文件合并存储到一个rados对象,rados对象元数据记录小文件在对象内的位置和偏移,小文件使用异步回收,通过顺序写提高性能。同时采用二级元数据方式减少元数据开销,提高空间利用率。 异步GC刚才也提到了,比如说已经有很多小文件,现在删了一个,中间就留下了一个空洞,当空洞越来越多的时候,到了一定的阈值,就重新去做一个拷贝,然后把剩下的数据聚合起来,重新形成一个连续的对象,把剩下的空间释放出来。(如下图) 这里还有一个上报服务的设计。因为我们要对外提供服务,所以我们需要定期上报用户的用量统计信息。这里我们利用了redis的分布式锁,上报服务可以在多个节点上同时运行,多个上报服务之间相互不感知,只通过redis分布式锁去做一个类似于抢占的模式,来保证不会上报有冲突,或者说同时去上报同一个用户信息。具体就是用到redis这样一个有续集的接口,针对每个用户,以用户的ID作为key,它的值就是这一次上报的时间。 那么每一个上报服务是怎么运行的?一来先用redis这个接口做一个排序,根据上次的上报时间做升序排列,最久没有上报的排在最前面,然后首先去抓列表里第一个元素来上报。因为大家都会做这个操作,因为大家相互不感知,但是来之前首先会加一把锁,如果加锁成功了,那就证明只有我会上报这个数据,别人就肯定不会上报。我就用redis分布式锁的机制,用一个set lock操作去尝试上这个锁。如果上锁成功,那么就上报数据,之后就重新把元素的值改成当前时间,然后再把锁清除。如果同时有另外一个上报服务也想上报这个数据,它会发现加锁失败,那么就自然跳过了上报,然后去找列表里的第二个元素上报,这样就保证了大家的一个互斥性。然后也保证了各个上报服务可以并行工作,提升上报的效率。(具体参考下图) 异地灾备的思想比较简单。(如下图)我们支持两机房,主要就是利用消息队列,主数据中心这边(A机房)存储完成之后,会向消息队列发送一个消息,告诉它我现在已经上传一个文件,包括访问的url是什么样的――这样一些信息。对应(B机房)这边的备份模块,它订阅了这样一个消息队列,就可以收到对应的发布消息。它知道A机房那边刚刚上传一个文件,访问的url,然后就可以用url把数据拉过来,存到这边,实现异地备份。 另外有一个比较棘手的问题。就是Ceph本身虽然确实比较好,但这种去中心化其实有一个通用的问题,就是当你集群扩容的时候,需要做数据迁移。这个问题跟一致性哈希类似,当集群扩容的时候,有些数据对应的哈希值就会改变,这就导致一个数据迁移。而数据迁移是我们非常不喜欢的,因为现在仅仅是做了一个扩容操作,就需要做大量的迁移,需要重新做平衡,这样会影响业务的性能。因为在后端的迁移操作会占用大量的IO带宽,所以这个问题我们也是想通过一个方式去解决。 简单介绍下Ceph的映射过程,它实际上是一个两级映射。首先一个Object的名字通过Hash映射到PG,PG(Placement Group)就是一个对象组。引入对象组的概念,避免了object与OSD的直接映射,减小了海量对象管理的复杂性,RADOS的许多操作是以PG为单位进行。 这个时候首先通过哈希映射到一个PGID上面,PGID再通过一个CRUSH算法,选出三组OSD(假如是三副本),其中第一个就是主的存储副本,其他为从副本。就是这样的一个过程。(如下图) (编辑:温州站长网) 【声明】本站内容均来自网络,其相关言论仅代表作者个人观点,不代表本站立场。若无意侵犯到您的权利,请及时与联系站长删除相关内容! |